Importing JSON and CSV Files
This page discusses how to import JSON and CSV files into Stardog.
Page Contents
The same Virtual Graph commands and mappings that are used for creating virtual graphs can be used to import data from delimited (CSV or TSV) and JSON files. It is not truly virtual, but is part of our Virtual Graph APIs and docs because it shares the same mappings syntax.
-
The mappings files for importing text files must be expressed in SMS2.
-
Unlike all other Virtual Graph data sources, the
WHEREclause in SMS2 mappings for text files supports any SPARQL query function whenBIND-ing transformed values to new variables. -
A user requires
WRITEpermission on a database in order to import JSON or CSV files. If Named Graph Security is enabled, they will also requireWRITEpermission on the named graph into which they want to import data.
Importing CSV Files
From the CLI:
To import a CSV file from the command line, provide the CSV file as the last argument to the virtual import command:
$ stardog-admin virtual import myDB cars.sms cars.csv
In the example above:
myDBis the database we are going to import the mapped CSV intocars.smsis the SMS2 mapping defining how the CSV will be mapped to RDFcars.csvis the CSV file to be imported
Using Stardog Studio:
It’s also possible to import CSV files using Stardog Studio. See Studio CSV Import Wizard for more information.
CSV Properties File
If the input file is using different kind of separators, e.g. tab character, a properties file can be provided in the virtual import CLI command:
$ stardog-admin virtual import myDB cars.properties cars.sms cars.tsv
- The properties file is a Java properties file.
The properties file for CSVs can specify values for the following virtual graph properties:
| Property | Description | Default |
|---|---|---|
csv.separator | character for separating fields | , |
csv.quote | The character used to enclose fields in a delimited file. Used for strings that contain field separator characters. To escape a CSV Quote character within a string that is enclosed in CSV Quote characters, use two consecutive CSV Quote characters | " |
csv.escape | character for escaping special characters | |
csv.header | boolean value for specifying whether or not the input file has a header line at the beginning | true |
csv.hash.function | the hash function to use for fields prefixed with a # | SHA1 |
csv.skip.empty | Whether to treat empty (zero-length) fields in delimited files as null | true |
unique.key.sets | the set of columns that uniquely identify each row | |
-
The
csv.escapecharacter is used as an alternative to thecsv.quotecharacter. To escape acsv.quotecharacter within a string that is enclosed incsv.quotecharacters, use two consecutivecsv.quotecharacters. Do not setcsv.escapeto thecsv.quotecharacter. -
Note that whitespace characters in the Java properties file format need to be escaped so if you want to import tab-separated value files set
csv.separator=\tin the properties file.
Example CSV Properties File
Suppose we wanted to import a TSV file without a defined header - we could include the following properties in our properties file:
cars.properties
csv.header=false
csv.separator=\t
CSV Mapping File
The mapping file for importing CSV files must be expressed in SMS2.
Unlike all other Virtual Graph data sources, the WHERE clause in SMS2 mappings for text files supports any SPARQL query function when BIND-ing transformed values to new variables
See the Example CSV Import for more details on creating a mapping.
- A mapping file can be omitted if a properties file is provided. See Automatically Generated Mappings for more information.
- The Studio CSV Import Wizard can also be used to quickly import CSV files without having to create an SMS2 mapping. Note, if more complex transformations are needed, you’ll need to create your own SMS2 mapping and import the CSV from the command line.
CSV Header with Dots and Spaces in Column Name
Stardog will allow you to import a CSV file that has column names containing .’s and spaces. If you are creating a mapping you’ll need to be able to refer to these column names in the TO and WHERE clauses. Stardog’s mapping parser will fail to parse a variable name like ?first.name to reference a CSV column name first.name
You have 2 options to refer to these column names containing .’s and spaces as variables in the mapping.
- Replace all occurrences of
.and spaces in variable names with an underscore (_) in mappings - Make use of the
sourceFieldfunction to return the name of the source field referred to by its string argument in theWHEREclause andBINDit to a new variable.
...
WHERE {
bind(sourceField("first.name") as ?firstName)
bind(sourceField("last name") as ?lastName)
}
Automatically Generated CSV Mappings
The mappings for delimited files can be automatically generated given a couple additional properties in the properties file:
| Property | Description |
|---|---|
csv.class | indicate the class, or rdf:type, to use for the subjects of each row |
unique.key.sets | the set of columns that uniquely identify each row |
To import with automatically generated mappings, omit the command line argument for the mappings file:
$ stardog-admin virtual import myDB cars.properties cars.csv
See the stardog-examples Github repository for an example virtual import that uses autogenerated mappings.
Studio CSV Import Wizard
Stardog Studio provides a “wizard”-like experience for quickly importing CSV data into Stardog. To get started, just choose a database under Studio’s “Databases” tab and click on “Import CSV.” Studio’s wizard will extract the headers (if any) from the CSV file you supply and will let you choose both a name for the class of data that the CSV represents (i.e.,the type of thing to which each row of the CSV corresponds) and the column that should be used for generating unique identifiers for instances of that class. To help you choose a truly unique identifier, the wizard will also show you just how distinct the data in each column of the CSV is, and will indicate whether or not the column you’ve chosen is likely to be a good one with respect to data integrity.
A user requires WRITE permissions to the database and READ permissions to the database’s metadata in order to invoke the Studio CSV Import Wizard. If Named Graph Security is enabled, they will also require WRITE permission on the named graph into which they want to import data.
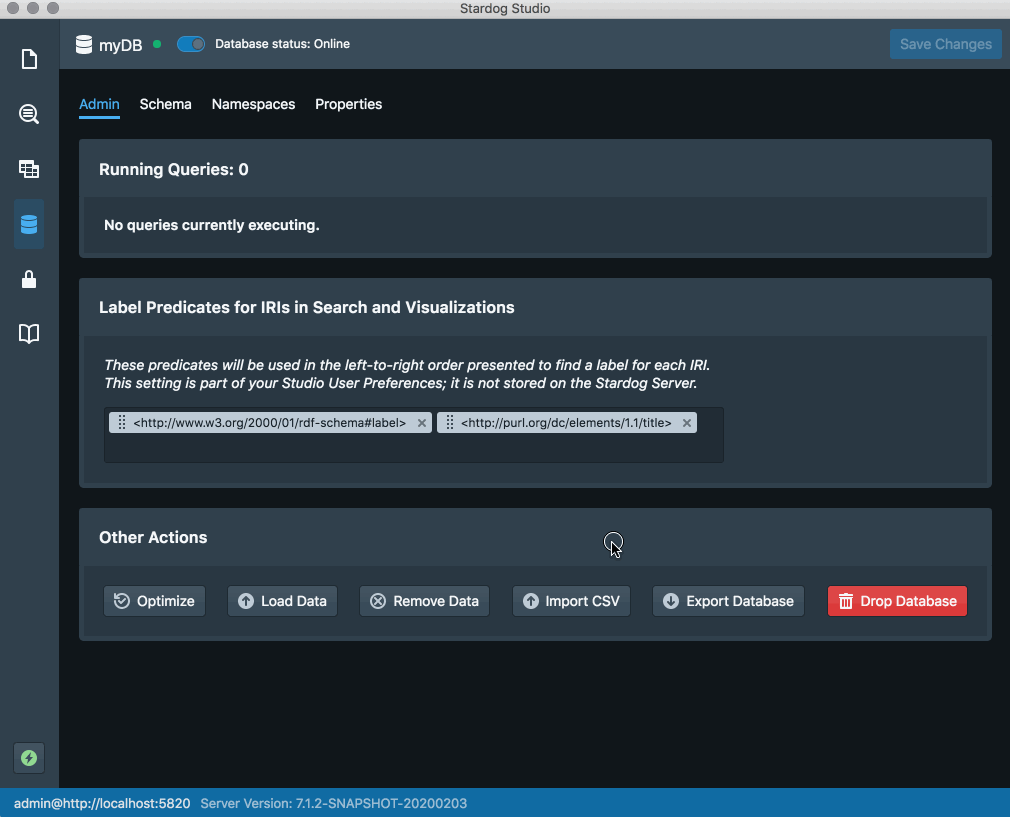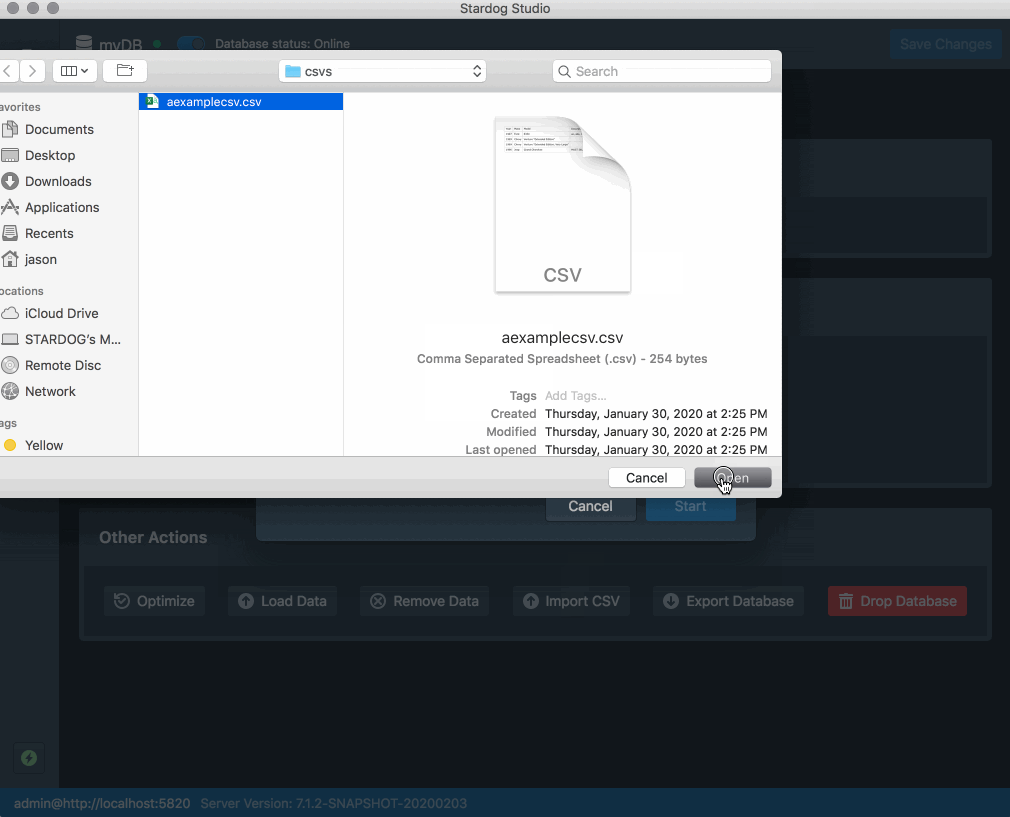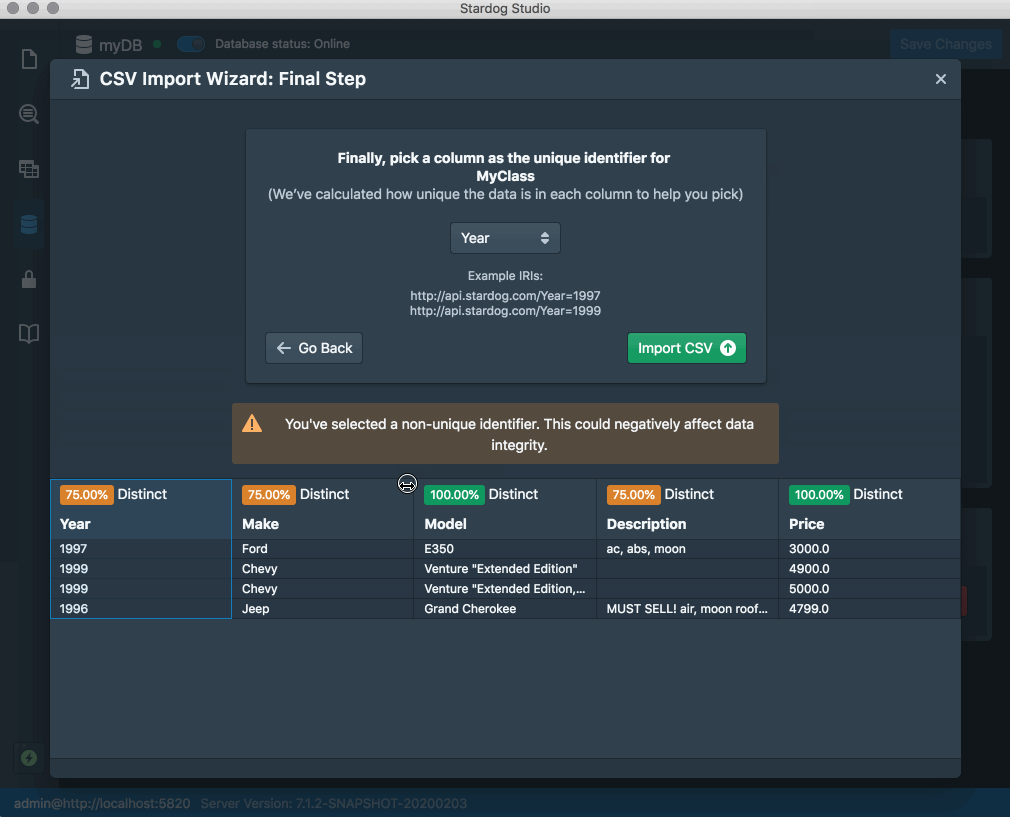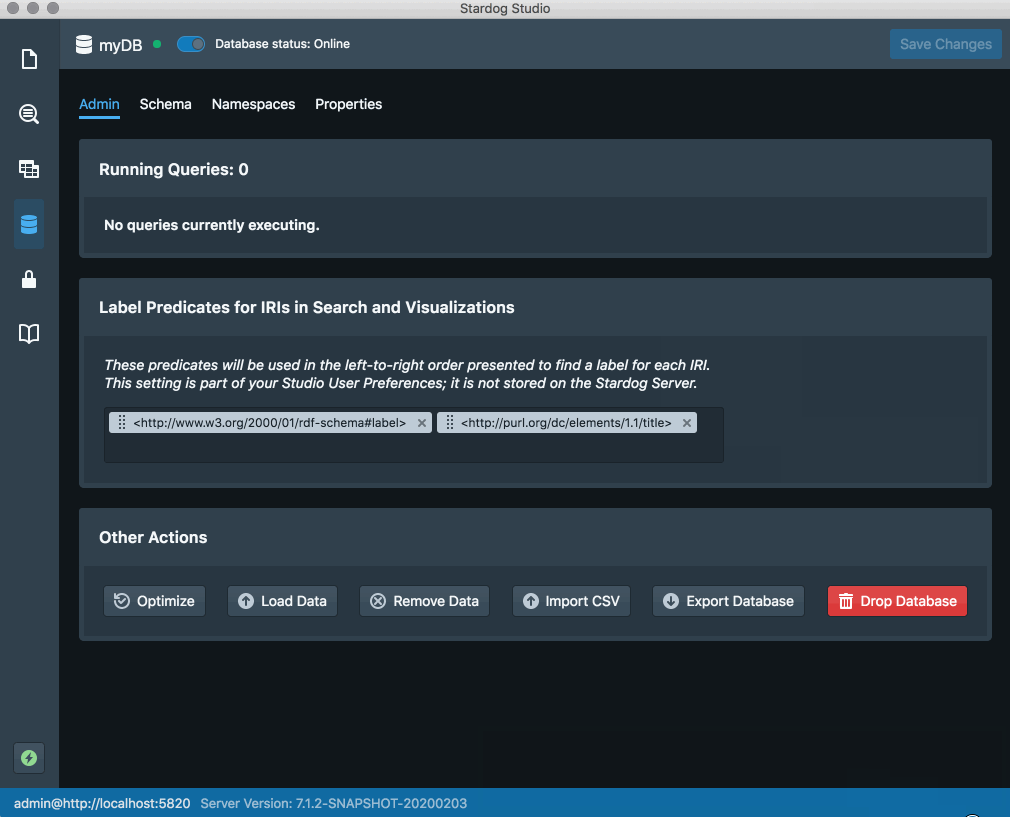
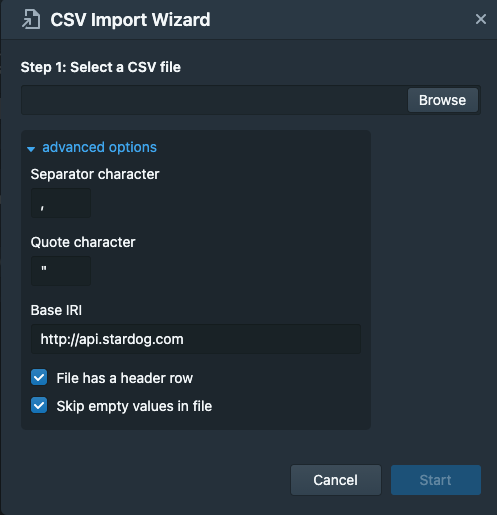
CSV Import Wizard Advanced Options
It’s possible to customize some properties when importing a CSV through the import wizard. When selecting your CSV file to import, unfold the “Advanced Options”
Example CSV Import
In this example, we’ll show how to put together the required elements to import a CSV file into Stardog.
The files used in this example can be found in the stardog-examples Github repository.
CSV file
We will use the following CSV file in the example.
cars.csv
Year,Make,Model,Description,Price
1997,Ford,E350,"ac, abs, moon",3000.0
1999,Chevy,"Venture ""Extended Edition""","",4900.0
1999,Chevy,"Venture ""Extended Edition, Very Large""",,5000.0
1996,Jeep,Grand Cherokee,"MUST SELL! air, moon roof, loaded",4799.0
- Note that lines 3 and 4 are missing Descriptions.
Omitting the CSV Properties File
We can omit a properties file in this example because the default CSV properties work just fine here. If we wanted to import a TSV, we’d need to specify this in the properties file.
Creating the CSV Mapping File
Recall the mapping files for importing CSV files must be expressed in SMS2. If you are not familiar with SMS2 please see the overview provided in Mapping Data Sources.
We could use the following mapping to map the CSV to RDF.
cars_mappings.sms
prefix : <http://example.org/cars#>
prefix gr: <http://purl.org/goodrelations/v1#>
prefix vso: <http://purl.org/vso/ns#>
MAPPING
FROM CSV {
}
TO {
?car_iri a vso:Automobile, gr:ActualProductOrServiceInstance ;
rdfs:label ?car_label ;
gr:hasManufacturer ?make_iri ;
gr:hasMakeAndModel ?model_iri ;
vso:modelDate ?model_date .
?make_iri a gr:BusinessEntity ;
rdfs:label ?Make .
?model_iri a gr:ProductOrServiceModel ;
rdfs:label ?model_string ;
gr:hasManufacturer ?make_iri .
?offer_iri a gr:Offering ;
rdfs:comment ?Description ;
gr:includes ?car_iri ;
gr:hasBusinessFunction gr:Sell ;
gr:hasPriceSpecification ?price_bnode .
?price_bnode a gr:UnitPriceSpecification ;
gr:hasCurrency "USD"^^xsd:string ;
:uuid ?uuidstr ;
gr:hasCurrencyValue ?price_float .
}
WHERE {
BIND(TEMPLATE("http://example.org/cars#Manufacturer-{Make}") AS ?make_iri)
BIND(TEMPLATE("http://example.org/cars#Model-{Model}") AS ?model_iri)
BIND(CONCAT(?Make, " ", ?Model) AS ?model_string)
BIND(CONCAT(?Make, " ", ?Model, " (", ?Year, ")") AS ?car_label)
BIND(TEMPLATE("http://example.org/cars#Car-{_ROW_NUMBER_}") AS ?car_iri)
BIND(TEMPLATE("http://example.org/cars#Offer-{_ROW_NUMBER_}") AS ?offer_iri)
BIND(xsd:float(?Price) AS ?price_float)
BIND(xsd:date(CONCAT(?Year, "-01-01")) AS ?model_date)
BIND(BNODE(CONCAT("price-", STRUUID())) AS ?price_bnode)
}
Let’s break this mapping down in further detail:
| Line Number(s) | Explanation |
|---|---|
| 6-7 | Use an empty FROM CSV clause to indicate this is a delimited input. |
| 8 | The TO clause defines how the output RDF should look. It is analogous to the CONSTRUCT portion of the SPARQL CONSTRUCT query. It consists of a set of triples where variables can be used in any position. |
| 33 | New variables can be created in the WHERE clause using the SPARQL BIND function. Column names are case-sensitive, and will be taken from the header row. If there is no header use ?0, ?1, ?2 … for column names. |
| 35-36 | Use the special TEMPLATE function to construct IRIs from column names. |
| 38-39 | The SPARQL CONCAT function can be used to build up new String variables from columns. |
| 41-42 | For delimited import (only), a special _ROW_NUMBER_ variable will contain the current ROW number of the CSV file. |
| 44 | Cast “Price” column from String to Float. |
| 46 | SPARQL functions like xsd:date and CONCAT can be combined as needed |
| 48 | The SPARQL BNODE function can be used to create blank nodes. An optional argument can supply the ID. The SPARQL UUID and STRUUID functions can be used to generate unique IRIs and Strings, respectively. |
Executing the virtual import CLI command
Finally, we can import our CSV file (cars.csv) into our database (carsDb) using the virtual import Stardog Admin CLI command like so:
$ stardog-admin virtual import carsDb cars_mappings.sms cars.csv
- Our mapping file (
cars_mappings.sms) is provided to map the CSV to the desired RDF.
Query the Imported CSV Data
Let’s verify our data was imported correctly by quickly executing the following query to find all instances of gr:BusinessEntity in the database. We expect there to be three - Ford, Chevy, and Jeep
PREFIX gr: <http://purl.org/goodrelations/v1#>
SELECT *
{
?businessEntity a gr:BusinessEntity
}
Results:
| businessEntity |
|---|
| http://example.org/cars#Manufacturer-Ford |
| http://example.org/cars#Manufacturer-Chevy |
| http://example.org/cars#Manufacturer-Jeep |
You can see a Turtle export of all data imported into the database in our stardog-examples.
Importing JSON Files
To import a JSON file into Stardog from the CLI, provide the JSON file as the final argument to the virtual import command like so:
$ stardog-admin virtual import myDB bitcoin.sms bitcoin.json
We’ll look at the JSON file (bitcoin.json) and mapping (bitcoin.sms) in more detail below.
JSON File
bitcoin.json
{
"hash": "00000000000000000028484e3ba77273ebd245f944e574e1d4038d9247a7ff8e",
"time": 1569266867591,
"block_index": 1762564,
"height": 575144,
"txIndexes": [
445123952,
445058113,
445054577,
445061250
]
}
JSON Mapping File
bitcoin.sms
PREFIX : <http://example.com/>
MAPPING
FROM JSON {
{
"hash" : "?hash",
"time" : "?time",
"block_index" : "?block_index",
"height" : "?height",
"txIndexes" : [ "?txIndex" ]
}
}
TO {
?block a :Block ;
:hash ?hash ;
:time ?dateTime ;
:height ?height ;
:includesTx ?tx .
?tx a :Tx ;
:index ?txIndex .
}
WHERE {
bind(xsd:dateTime(?time) as ?dateTime)
bind(template("http://example.com/tx/{txIndex}") as ?tx)
bind(template("http://example.com/block/{hash}") as ?block)
}
Let’s break this mapping down in further detail:
| Line Number(s) | Explanation |
|---|---|
| 4-12 | The structure of the FROM JSON clause closely resembles the source JSON structure with some changes - these are described in more detail in Mapping Data Sources. |
| 13-21 | The TO clause defines how the output RDF should look. This is the mapping target. It is analogous to the CONSTRUCT portion of the SPARQL CONSTRUCT query. It consists of a set of triples where variables can be used in any position. |
| 23 | The WHERE clause is where you can transform source data and BIND the transformed values to new variables. |
| 24 | Cast the “time” field from a String to xsd:dateTime and bind to a new variable - dateTime. |
| 25-26 | Construct IRIs using the TEMPLATE function and BIND them to new variables. |
Verify the JSON Import
We can export the data in Turtle to verify the structure of the data we just imported:
$ stardog data export myDB
@prefix : <http://api.stardog.com/> .
@prefix stardog: <tag:stardog:api:> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
<http://example.com/block/00000000000000000028484e3ba77273ebd245f944e574e1d4038d9247a7ff8e> a <http://example.com/Block> ;
<http://example.com/hash> "00000000000000000028484e3ba77273ebd245f944e574e1d4038d9247a7ff8e" ;
<http://example.com/time> "2019-09-23T19:27:47.591Z"^^xsd:dateTime ;
<http://example.com/height> 575144 ;
<http://example.com/includesTx> <http://example.com/tx/445123952> , <http://example.com/tx/445058113> , <http://example.com/tx/445054577> , <http://example.com/tx/445061250> .
<http://example.com/tx/445123952> a <http://example.com/Tx> ;
<http://example.com/index> 445123952 .
<http://example.com/tx/445058113> a <http://example.com/Tx> ;
<http://example.com/index> 445058113 .
<http://example.com/tx/445054577> a <http://example.com/Tx> ;
<http://example.com/index> 445054577 .
<http://example.com/tx/445061250> a <http://example.com/Tx> ;
<http://example.com/index> 445061250 .