Geo Replica Nodes (Feature Preview)
This page describes Geo Replica Nodes in Stardog - a useful feature for maintaining HA clusters.
Page Contents
Overview
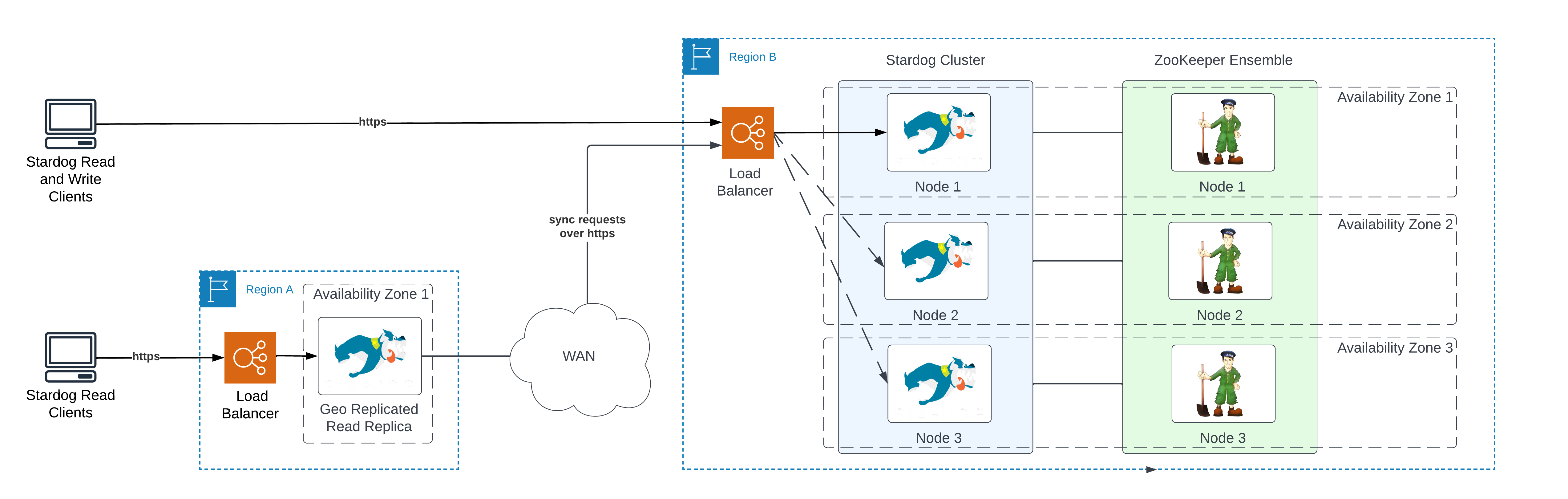
The notion of a geo replica node was introduced in Stardog 9.0. A geo replica node runs outside the data center or region where Stardog Cluster is running and periodically requests updates, as shown in the figure above. A geo replica can operate in read replica mode, or simply as a standby node. It cannot service any user write requests. Similar to a standby node, a geo replica stays closely synchronized with the cluster but without disturbing the cluster with the more difficult join event. By only drifting from full synchronization by limited time windows, it allows for a few important features:
-
A geo replica is designed to run outside the data center where Stardog Cluster is running. This is an important feature for disaster recovery and maintaining high-availability when an entire region is unavailable.
-
When configured as a read replica, the geo replica node can respond to SPARQL queries with minimal impact on the cluster. Note that the query results may not be exactly the same as those returned by the cluster, since the replica’s databases may be slightly out of date.
-
The replica node can safely run database and server backups while taking minimal CPU cycles from cluster nodes servicing user requests.
A geo replica node cannot be upgraded to be a full node in the cluster. Instead, a geo replica would need to be configured as a separate, independent, cluster with its own ZooKeeper deployment (or started as a standalone Stardog node) if you want to enable write requests in another region. However, at this point it will be completely separated from the original cluster, and if it is configured as a replica again, data loss may occur.
Configuring a Geo Replica
A geo replica is a single-node Stardog configured with the following settings in stardog.properties:
pack.enabled=true
pack.geoReplica=true
pack.geoReplica.address=<Stardog source cluster IP>:5820
pack.geoReplica.connection.user=<Stardog source cluster superuser>
pack.geoReplica.connection.password=<Stardog source cluster superuser password>
The geo replica address is the IP or domain name of the source Stardog Cluster endpoint and port (typically this is the load balancer). By default, geo replicas will sync over HTTPS to the address provided for the cluster. The geo replica requires a Stardog superuser and password to connect to the Stardog cluster endpoint and sync. The standby sync interval is the frequency that the geo replica attempts to sync from the primary cluster. Because the credentials are provided in stardog.properties, we recommend that the file is only readable to Stardog and that the file system is encrypted.
If you need to test a geo replica without HTTPS for non-production use cases, you can pass the flag --insecure-geo-replica to the stardog-admin server start command when Stardog starts, and syncs will happen over HTTP.
Do not use the --insecure-geo-replica flag in production environments or across wide-area networks with sensitive data. All Stardog data and metadata will be sent unencrypted over HTTP.
If you wish to configure the geo replica as a read replica, you can also specify:
pack.readReplica=true
To change the interval at which the geo replica syncs, you can change the standby sync interval (default is 5 minutes):
pack.standby.node.sync.interval=10m
Using a Geo Replica
A geo replica node functions similar to a standby node (or read replica if configured as one) except that it can run in another region. Therefore, working with a geo replica uses all the standby commands. Two key commands for working with geo replicas are cluster standby-status, which shows how far out of date different databases are, and cluster standby-attempt-sync, which will trigger a sync attempt immediately.
Similar to standby nodes and read replicas, stardog-admin server stop should be sent directly to the geo replica or SIGTERM sent to the process to shut it down.