External Compute
This chapter discusses External Compute - one of Stardog’s features for pushing heavy workloads to compute platforms like Databricks. This page primarily discusses what is external compute, how it works, and what are the supported operations. See the Chapter Contents for a short description of what else is included in this chapter.
Page Contents
Overview
Stardog supports operations where the workload can be pushed to external compute platforms.
The Supported Compute Platform is Databricks.
Supported Operations are:
- Virtual Graph Materialization using
virtual-importCLI command and SPARQL Update Queries (add/copy) - Virtual Graph Cache using
cache-createandcache-refreshCLI commands - Resolve Entities using
entity-resolution resolveCLI command
How it Works
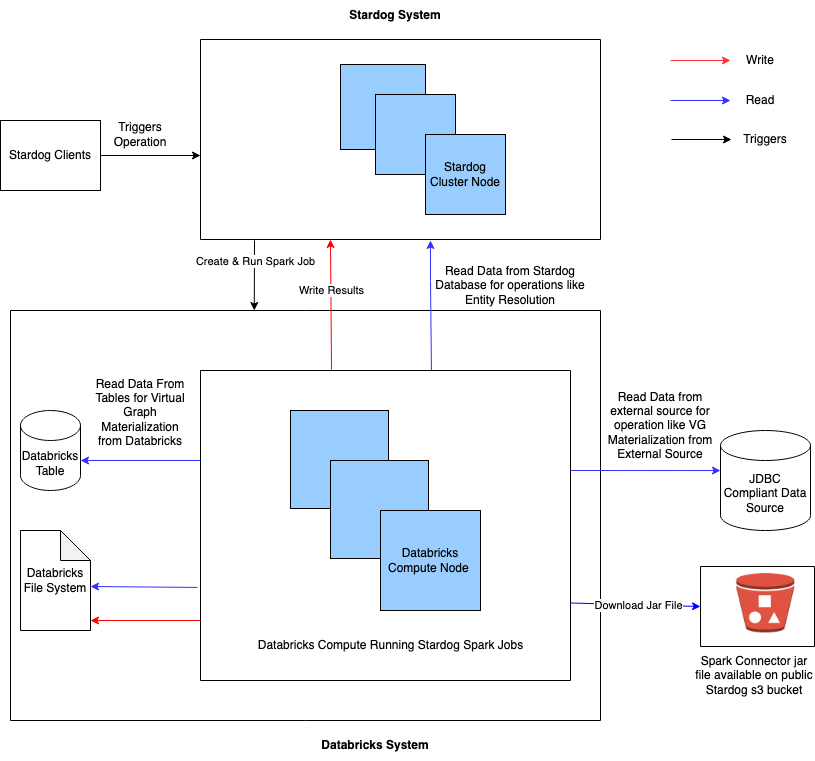
Stardog converts the supported operation into a Spark job, connects to the external compute platform, uploads the stardog-spark-connector.jar, and then creates and triggers the Spark job. This Spark job does the required computation on the external compute platform and then connects back to the Stardog server (using the user’s credentials that triggered the operation) to write the results to Stardog.
The Stardog Platform uploads the latest compatible stardog-spark-connector.jar version when the external compute supported operation is triggered if this jar is not on the compute platform. For more information on various configurations available around the stardog-spark-connector.jar, please refer to Configuring External Compute Datasource
If the older version of stardog-spark-connector.jar is available on the compute platform, uninstall the older version. Refer to the compute platform documentation on how to uninstall the libraries.
Compatibility Table:
| Stardog Platform Versions | Compatible stardog-spark-connector Versions |
|---|---|
| 8.2.* | 2.0.0 |
| 9.0.* | 3.0.0 |
stardog-spark-connector-3.0.* requires Java 11. Therefore, please set Java Version to JAVA 11 in the external compute platform. E.g., for Databricks, set JNAME=zulu11-ca-amd64 as the Spark environment variable in compute.
Architecture
The high-level architecture for external compute is as shown:
Chapter Contents
- Databricks Configuration - discusses configuring Databricks as an external compute platform in Stardog
- Virtual Graph Materialization - discusses how to materialize Virtual Graphs using external compute platform in Stardog
- Entity Resolution - discusses how to resolve entities using external compute platform in Stardog. This feature is in Beta