Virtual Graph Materialization
This page discusses how to materialize virtual graph using external compute platform.
Materialize the virtual graph using the virtual-import CLI command and SPARQL Update Queries (add/copy).
Supported virtual graph data sources are:
- JDBC data source supported in Stardog
- CSV files accessible from external compute platform
- Spark Tables
To use the JDBC data source, establish connectivity of the external compute platform with the data source, and configure the respective JDBC jars.
Overview
The materialization operation of the virtual graph gets converted into a Spark job. This Spark job will be created and triggered on an external-compute platform. The Spark job is dependent on the stardog-spark-connector jar. If this jar is not on the external compute platform the Stardog server will upload the latest compatible version of the stardog-spark-connector.jar based on the configured options. The options vary as per the external compute platform. Please refer the following sections as per the external compute platform.
Then the Spark job will connect to the source, read the data, apply virtual graph mappings and write back the resultant triples into the Stardog database.
Options
| Option | Description |
|---|---|
| compute | Name of the data source registered as External Compute Platform for databricks and the absolute path to a properties file for emr-serverless. |
| partition-column | This option is only valid for JDBC data sources and supports the single-column name. If there is more than one mapping in the Virtual Graph or the provided mapping file referring to a different column name, try one of these options: 1) All the tables used in mappings should have a column with the same name, e.g., ID. 2) Create multiple Virtual Graphs, i.e., each mapping contains only one table, and consider running multiple external compute operations. |
partition-column should be numeric and should have an even distribution of values. Please refer to spark-docs for more details on the partition column.
virtual-import
A new option, compute, is added in the virtual-import command. The materialization workload is pushed to the external compute platform when this option is present. Set the option to the data source name registered as an external-compute platform using data-source options for databricks or compute options for emr-serverless.
To materialize a Virtual Graph using the JDBC source
$ stardog-admin virtual import --compute myDatabricks -s myVGSource myDB myVGMapping.sms
$ stardog-admin virtual import --compute <path-to>/emr-serverless-config.properties -s myVGSource myDB myVGMapping.sms
To materialize a Virtual Graph using JDBC source with partition-column
$ stardog-admin virtual import --compute myDatabricks -s myVGSource myDB myVGMapping.sms --partition-column ID
$ stardog-admin virtual import --compute <path-to>/emr-serverless-config.properties -s myVGSource myDB myVGMapping.sms --partition-column ID
To materialize a Virtual Graph using a CSV file on an external compute platform
$ stardog-admin virtual import --compute myDatabricks myDB myVGMappings.sms /FileStore/myData.csv
$ stardog-admin virtual import --compute <path-to>/emr-serverless-config.properties myDB myVGMappings.sms /<path-to-s3bucket>/myData.csv
To materialize the spark tables on the external compute platform
$ stardog-admin virtual import --compute myDatabricks myDB myDatabricks.properties myDatabricks.sms
$ stardog-admin virtual import --compute <path-to>/emr-serverless-config.properties myDB myDatabricks.properties myDatabricks.sms
Properties file example:
jdbc.url=jdbc:spark://adb-XXXXXX.XX.azuredatabricks.net:443/default;transportMode=http;ssl=1;AuthMech=3;httpPath=/sql/1.0/endpoints/XXXXXXX;
jdbc.username=xxxx
jdbc.password=xxxxx
jdbc.driver=com.simba.spark.jdbc.Driver
sql.schemas=*
SPARQL update queries
External compute options can be passed as Query Hints in SPARQL update (add/copy) queries. These hints are the suggestions to the query optimizer so that the query engine pushes add/copy operations for virtual graphs to an external-compute platform.
To add the virtual graph using external compute
#pragma external.compute.name myDatabricks
ADD <virtual://MyVg> TO :OtherNamedGraph
#pragma external.compute.props stardog.external.compute.platform=emr-serverless;stardog.external.aws.region=us-east-2;stardog.external.aws.access.key=ASIXXXXXXXXXXNP;stardog.external.aws.secret.key=KZQA205ma/pYtLoSxIWrL9oEwX/ut0LAPfAOIFs+;stardog.external.aws.session.token=FwoGZXIvYXdzEFwaDEeDmjJwi;stardog.external.emr-serverless.application.id=00fa02fbl2qujv09;stardog.external.emr-serverless.execution.role.arn=arn:aws:iam::626720994556:role/emraccess;stardog.host.url=http://ec2-44-204-114-111.compute-1.amazonaws.com:5820;stardog.external.jar.path=s3://stardog-spark/stardog-spark-connector-3.1.0.jar
ADD <virtual://MyVg> TO :OtherNamedGraph
To copy the virtual graph using external compute
#pragma external.compute.name c
COPY <virtual://MyVg> TO :OtherNamedGraph
#pragma external.compute.props stardog.external.compute.platform=emr-serverless;stardog.external.aws.region=us-east-2;stardog.external.aws.access.key=ASIAZD233NYFSCZSMANP;stardog.external.aws.secret.key=KZQA205ma/pYtLoSxIWrL9oEwX/ut0LAPfAOIFs+;stardog.external.aws.session.token=FwoGZXIvYXdzEFwaDEeDmjJwi;stardog.external.emr-serverless.application.id=00fa02fbl2qujv09;stardog.external.emr-serverless.execution.role.arn=arn:aws:iam::626720994556:role/emraccess;stardog.host.url=http://ec2-44-204-114-111.compute-1.amazonaws.com:5820;stardog.external.jar.path=s3://stardog-spark/stardog-spark-connector-3.1.0.jar
COPY <virtual://MyVg> TO :OtherNamedGraph
To copy the virtual graph using external compute along with partition column option
#pragma external.compute.name myDatabricks
#pragma external.compute.partition.column ID
COPY <virtual://MyVg> TO :OtherNamedGraph
cache-create
A new option, compute, is added in the cache-create command. Cache Creation workload is pushed to the external compute platform when this option is present. Set the options to the data source name registered as an external compute platform using data-source options for databricks or compute options for emr-serverless.
The Cache target can not be set to localhost.
To create a cache using external compute
$ cache-create cache://mycache --graph virtual://myVG --target myTarget --compute myDatabricks
$ cache-create cache://mycache --graph virtual://myVG --target myTarget --compute <path-to>/emr-serverless-config.properties
To create a cache using external compute with the partition column provided virtual graph source is JDBC
$ cache-create cache://mycache --graph virtual://myVG --target myTarget --compute myDatabricks --partition-column ID
$ cache-create cache://mycache --graph virtual://myVG --target myTarget --compute <path-to>/emr-serverless-config.properties --partition-column ID
To Refresh the cache
$ cache-refresh cache://mycache
The refresh-script option is not supported with caches that were created using external compute.
Spark Job details
As discussed in various sections like overview, How it Works, and Architecture, Stardog creates a new Spark job for each executed external compute-supported operation. This section describes the details around the Spark job.
The name of the Spark job will be of the format: Stardog<OperationName><VirtualGraphName><Timestamp>
E.g., StardogMaterializationMyVG11668700425701, in this example, Materialization is the operation name, and MyVG is the name of the virtual graph followed by the timestamp when Stardog created this job.
The external compute platform will list the Spark jobs created by Stardog under their workflow/jobs management. E.g. in the case of Databricks, these jobs are visible under the workflows as shown:
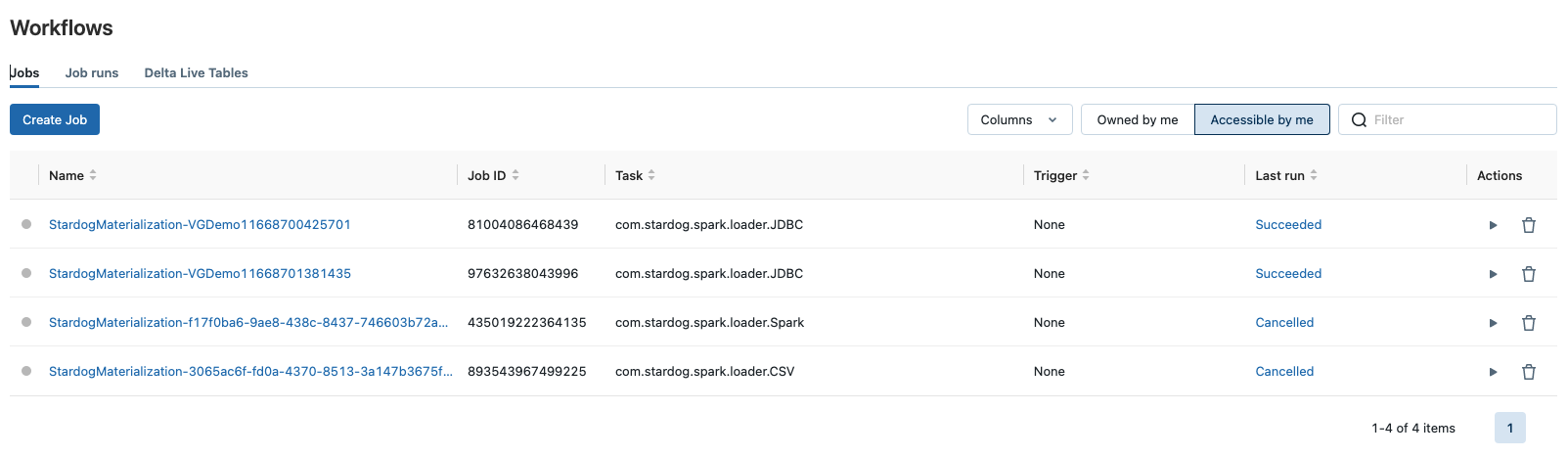
For emr-serverless, the jobs are listed in EMR Studio’s application as shown: 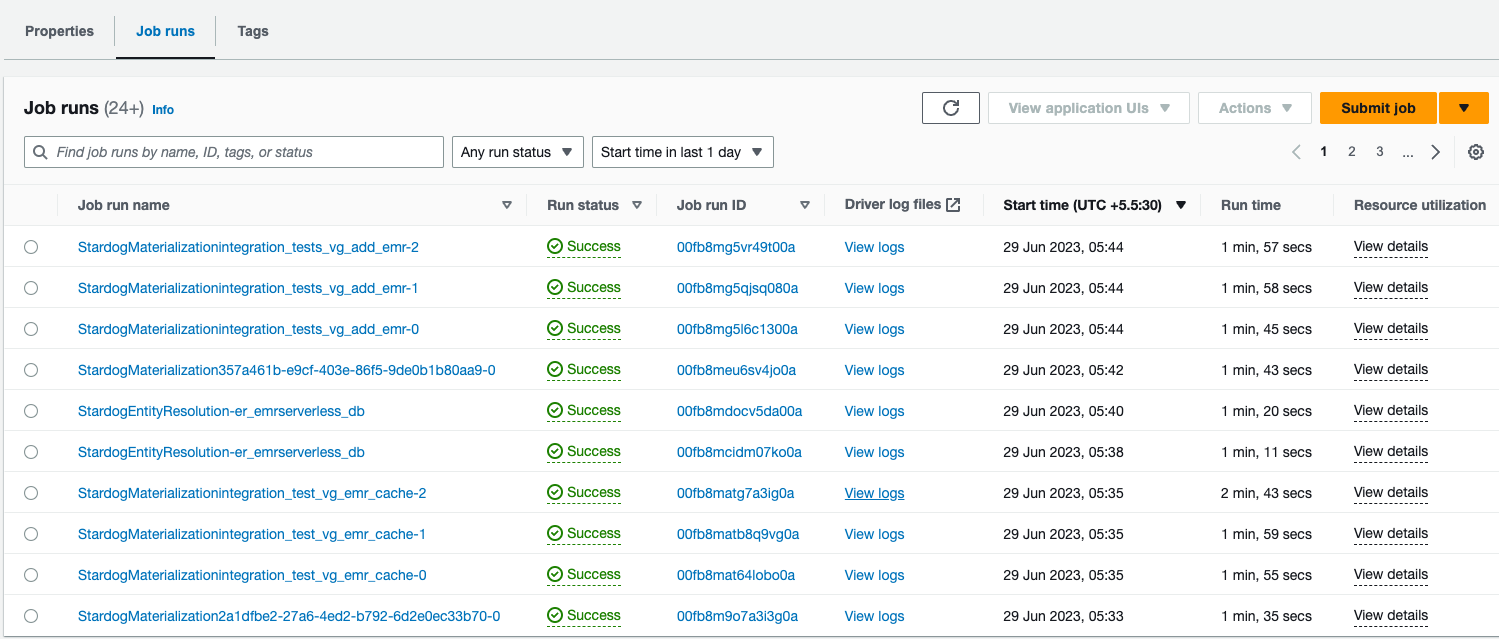
Each Spark job created by the Stardog will have only one task with the same name as that of the job. For E.g., in case of Databricks, the task is visible under the job as shown:
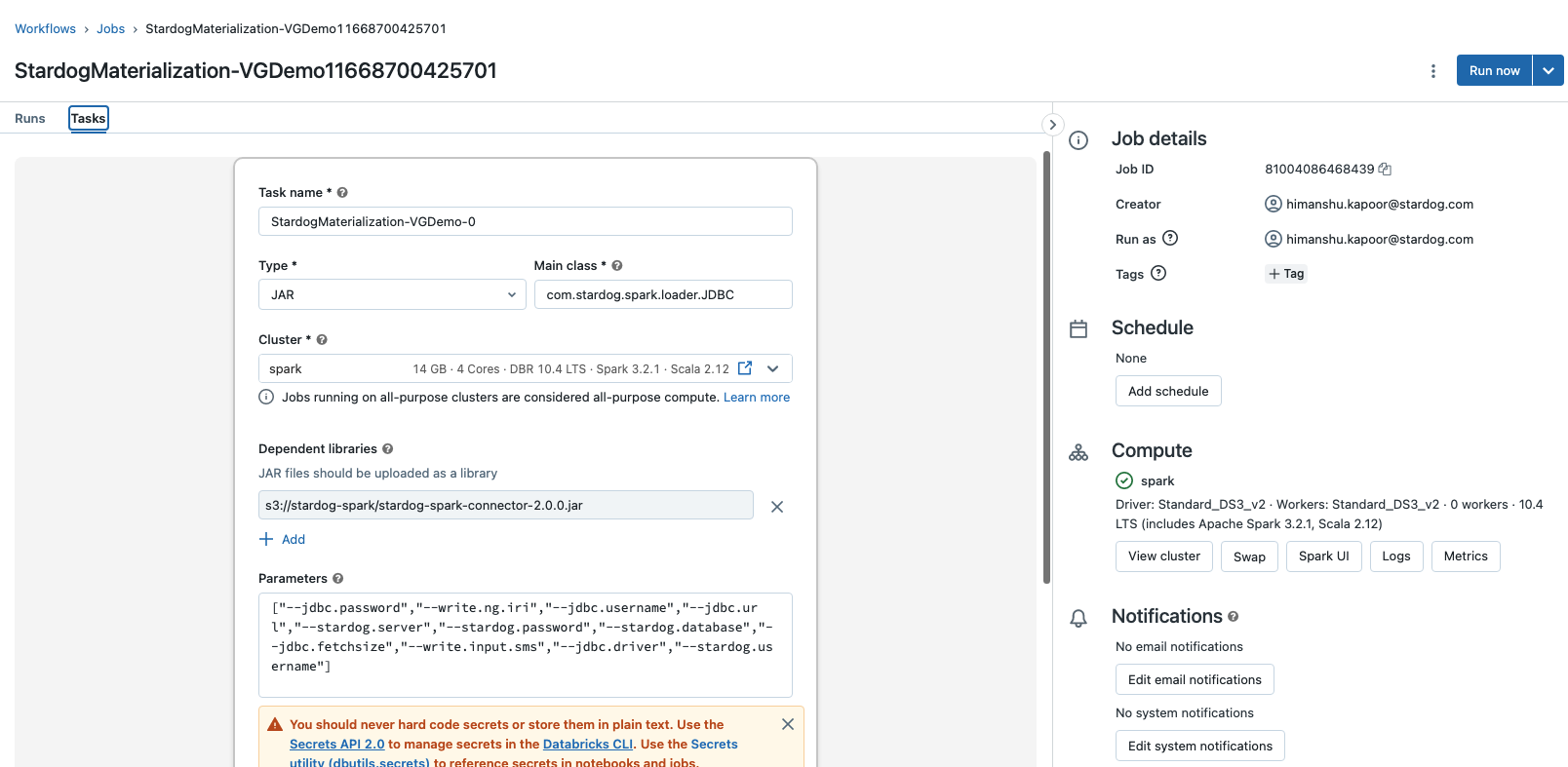
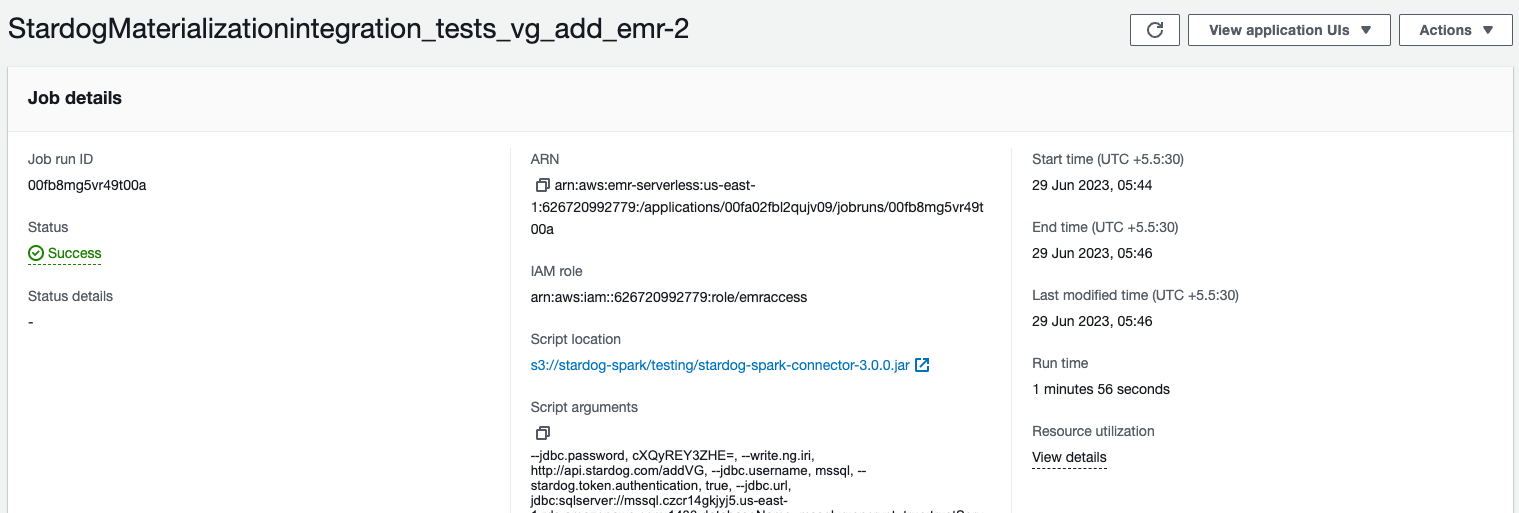
In case of emr-serverless, we can click on the job to view the details.
Stardog will trigger multiple runs of the created Spark job in case there is more than one mapping in the Virtual Graph or the provided mapping file. E.g., in the case of Databricks, the multiple runs are visible as shown:
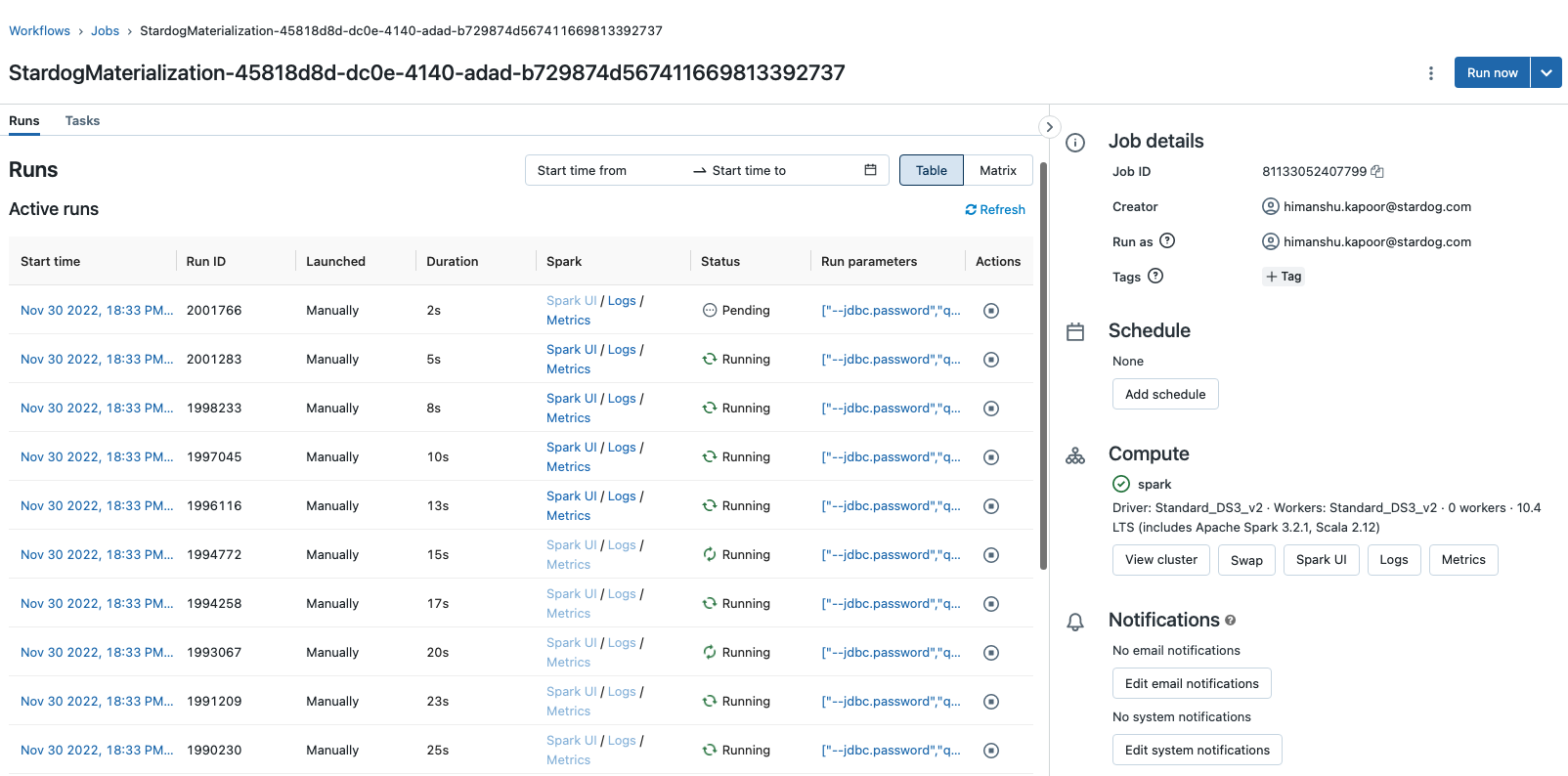
Stardog converts the virtual graph materialization configuration like source details, mapping, and Stardog details into job parameters and then pass these parameters at runtime to the Spark job. These job parameters are generated automatically by Stardog.
List of job parameters:
| parameter name | Description |
|---|---|
| jdbc.url | URL of the JDBC data source. This is only passed when the source of the Virtual Graph is JDBC. |
| jdbc.username | Datasource user configured in Stardog. Spark job will use this user name to authenticate into the JDBC database. This is only passed when the source of the Virtual Graph is JDBC. |
| jdbc.password | Datasource password configured in Stardog. Stardog encrypts the password while passing this parameter over a secured REST HTTPS call. Spark job will use this password to authenticate into the JDBC database. This is only passed when the source of the Virtual Graph is JDBC. |
| jdbc.driver | JDBC driver class name. This is only passed when the source of the Virtual Graph is JDBC. |
| stardog.server | Stardog server URL from where external compute operation is triggered. The Spark job will connect back to this URL to write the results. |
| stardog.username | Stardog user who has triggered the external compute operation. Spark job will use this user name to authenticate into the Stardog server. |
| stardog.password | Auth token of the Stardog user who has triggered the external compute operation. Stardog encrypts this token while passing this parameter over a secured REST HTTPS call. Spark job will use this auth token to authenticate into the Stardog server. |
| stardog.database | Stardog Database name. Spark job will connect this database to write back the results. |
| write.ng.iri | Named Graph. |
| write.input.sms | This parameter refers to the path of the mapping file uploaded by Stardog. Spark job will apply this mapping to generate results. |
| csv.location | Location of the CSV file on the dbfs. This is only passed when the source of the Virtual Graph is JDBC. |