Cluster
This chapter discusses how to configure, use, and administer a Stardog Cluster for uninterrupted operations.
Page Contents
Overview
Stardog Cluster is a collection of Stardog Server instances running on one or more virtual or physical machines that, from the client’s perspective, behave like a single Stardog Server instance. “Client” here means the client of Stardog APIs. To fully achieve this effect requires DNS (i.e., with SRV records) and proxy configuration that’s left as an exercise for the user.
Of course Stardog Cluster should have some different operational properties, the main one of which is high availability. But from the user’s perspective Stardog Cluster should be indistinguishable from non-clustered Stardog. While Stardog Cluster is primarily geared toward HA, it is also important to remember that it should be tuned for your specific use case.
Our detailed blog post discusses a variety of factors that you should consider when deploying Stardog Cluster as well as some adjustments you should make depending on your workload.
Architecture
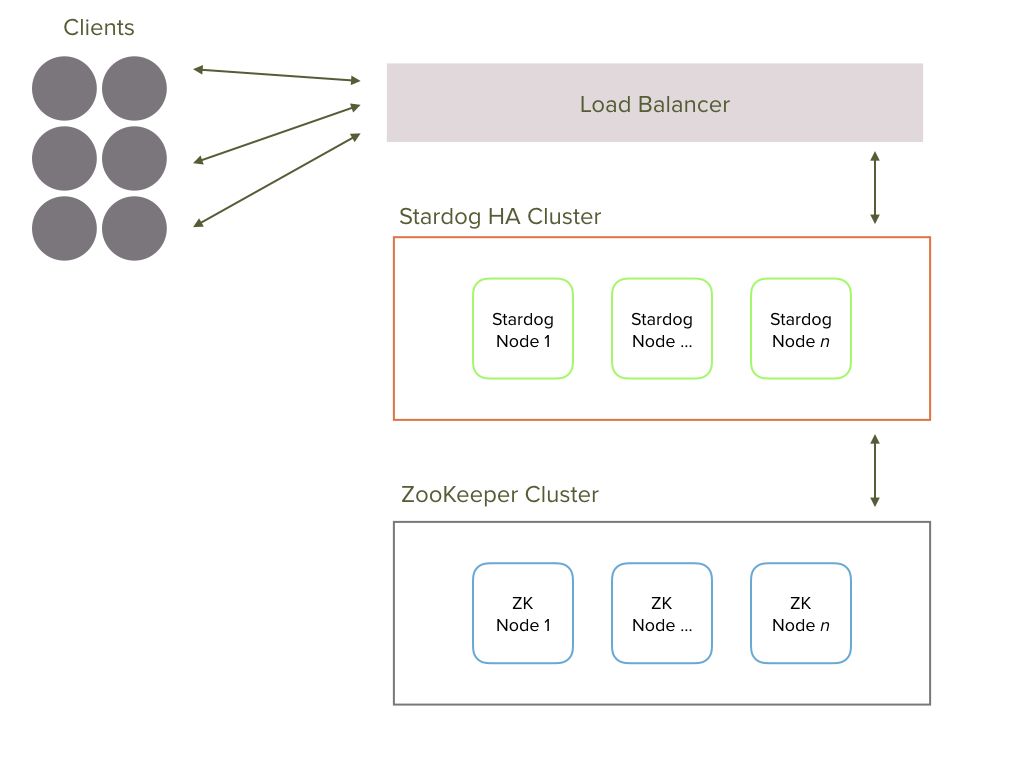
Stardog Cluster depends on Apache ZooKeeper. High Availability requires at least three Stardog and three ZooKeeper nodes in the Cluster. ZooKeeper works best, with respect to fault resiliency, with an ensemble size that is an odd-number greater than or equal to three: 3, 5, 7, etc. See ZK Admin for more details.
With respect to performance, larger Stardog clusters perform better than smaller ones for reads, while larger cluster sizes perform worse for writes. It is the responsibility of the administrator to find the right balance.
Guarantees
A cluster is composed of a set of Stardog servers and a ZooKeeper ensemble running together. One of the Stardog servers is the Coordinator and the others are Participants. The Coordinator orchestrates transactions and maintains consistency by expelling any nodes that fail an operation. An expelled node must sync with a current member to rejoin the cluster.
In case the Coordinator fails at any point, a new Coordinator will be elected out of the remaining available Participants. Stardog Cluster supports both read (e.g., querying) and write (e.g., adding data) requests. All read and write requests can be handled by any of the nodes in the cluster. When a client commits a transaction (containing a list of write requests), it will be acknowledged by the receiving node only after every non-failing peer node has committed the transaction. If a peer node fails during the process of committing a transaction, it will be expelled from the cluster by the Coordinator and put in a temporary failed state. If the Coordinator fails during the process, the transaction will be aborted. At that point the client can retry the transaction and it should succeed with the new cluster coordinator.
Since failed nodes are not used for any subsequent read or write requests, if a commit is acknowledged, then Stardog Cluster guarantees that the data has been accordingly modified at every available node in the cluster.
While this approach is less performant with respect to write operations than eventual consistency used by other distributed databases, typically those databases offer a much less expressive data model than Stardog, which makes an eventually consistency model more appropriate for those systems (and less so for Stardog). But since Stardog’s data model is not only richly expressive but rests in part on provably correct semantics, we think that a strong consistency model is worth the cost