Entity Resolution
This page discusses how to resolve entities using external compute platform. This feature is in Beta.
Page Contents
Resolve the entities using the entity-resolution resolve CLI command. External compute is the recommended way to use the entity-resolution functionality.
Overview
The entity resolution operation gets converted into a Spark job. This Spark job will be created and triggered on an external-compute platform. The Spark job is dependent on the stardog-spark-connector.jar. If this jar is not on the external compute platform the Stardog server will upload the latest compatible version of the stardog-spark-connector.jar based on the configured options. The options vary as per the external compute platform. Please refer the following sections as per the external compute platform.
The Spark on Kubernetes provider does not auto-upload the connector jar — the mainApplicationFile in the customer-supplied SparkApplication template must reference a jar reachable by the driver pod. See Spark on Kubernetes Configuration for details.
Once the jar is properly uploaded, the Spark job will connect to the Stardog server, execute the query provided by the user, read the entities and run the entity resolution process, and finally write the resolution results in the form of RDF triples back into the Stardog database.
Options
| Option | Description |
|---|---|
| compute | Name of the data source registered as External Compute Platform for databricks, or the absolute path to a properties file for emr-serverless and spark-k8s. |
Resolve
When the compute option is added to the entity-resolution resolve command the resolve workload is pushed to the external compute platform. Set the option to the data source name registered as an external-compute platform using data-source options for databricks, or to the path of a properties file for emr-serverless and spark-k8s.
To resolve entities on databricks:
$ stardog entity-resolution resolve myDB "select *
{
?person a :Person ;
:given_name ?given_name ;
:surname ?surname ;
:date_of_birth ?date_of_birth;
:phone_number ?phone_number ;
:age ?age .
?address a :Address ;
:street_number ?street_number ;
:address_1 ?address_1 ;
:address_2 ?address_2 ;
:suburb ?suburb ;
:postcode ?postcode ;
:state ?state .
}" person test:myTargetNamedGraph --compute myDatabricksExternalComputeDatasource
To resolve entities on emr-serverless:
$ stardog entity-resolution resolve myDB "select *
{
?person a :Person ;
:given_name ?given_name ;
:surname ?surname ;
:date_of_birth ?date_of_birth;
:phone_number ?phone_number ;
:age ?age .
?address a :Address ;
:street_number ?street_number ;
:address_1 ?address_1 ;
:address_2 ?address_2 ;
:suburb ?suburb ;
:postcode ?postcode ;
:state ?state .
}" person test:myTargetNamedGraph --compute <path-to>/emr-serverless-config.properties
To resolve entities on Spark on Kubernetes:
$ stardog entity-resolution resolve myDB "select *
{
?person a :Person ;
:given_name ?given_name ;
:surname ?surname ;
:date_of_birth ?date_of_birth;
:phone_number ?phone_number ;
:age ?age .
?address a :Address ;
:street_number ?street_number ;
:address_1 ?address_1 ;
:address_2 ?address_2 ;
:suburb ?suburb ;
:postcode ?postcode ;
:state ?state .
}" person test:myTargetNamedGraph --compute <path-to>/spark-k8s-config.properties
To include match score in the output:
$ stardog entity-resolution resolve myDatabase "select *
{
?person a :Person ;
:given_name ?given_name ;
:surname ?surname ;
:date_of_birth ?date_of_birth;
:phone_number ?phone_number ;
:age ?age .
?address a :Address ;
:street_number ?street_number ;
:address_1 ?address_1 ;
:address_2 ?address_2 ;
:suburb ?suburb ;
:postcode ?postcode ;
:state ?state .
}" person test:myTargetNamedGraph --compute myDatabricksExternalComputeDatasource --include-score true
Spark Job details
As discussed in various sections like Overview, How it Works, and Architecture, Stardog creates a new Spark job for each executed external compute-supported operation. This section describes the details around the Spark job.
The name of the Spark job will be of the format: Stardog<OperationName>-<Database><Timestamp>
E.g., StardogEntityResolution-MyDB11668700425701, in this example, EntityResolution is the operation name, MyDB is the name of the database, and 11668700425701 is the timestamp when Stardog created this job.
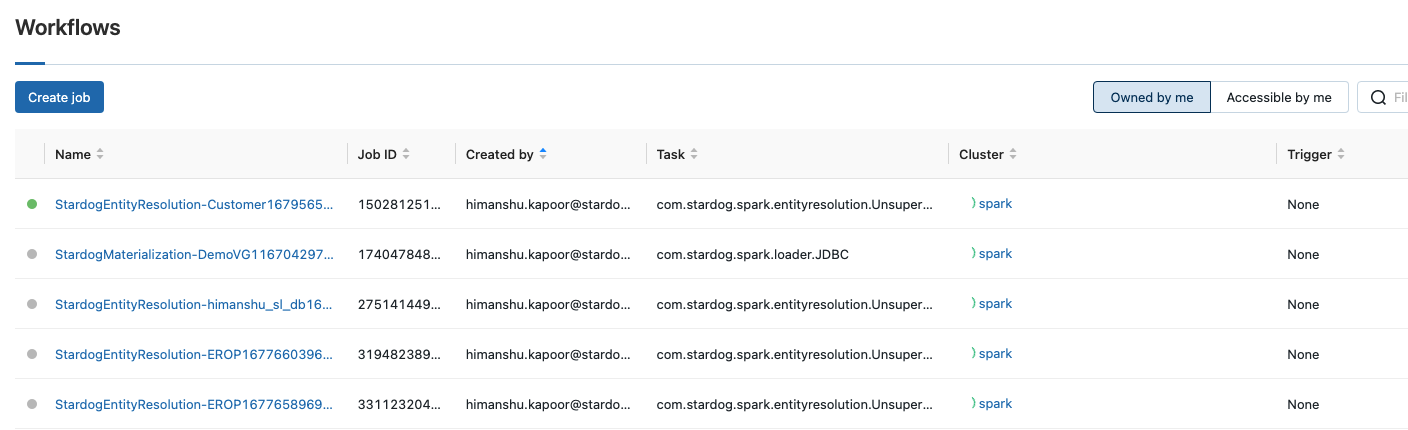
The external compute platform will list the Spark jobs created by Stardog under their workflow/jobs management. E.g. in the case of Databricks, these jobs are visible under the workflows as shown:
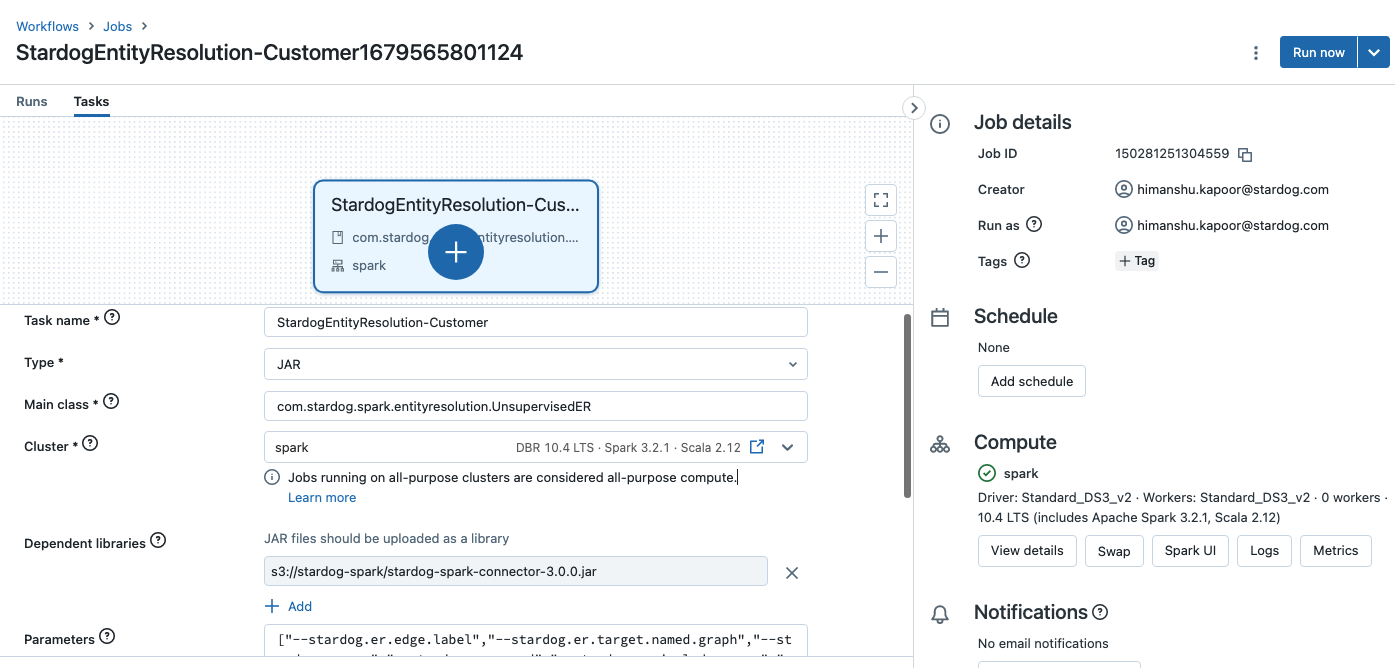
Each Spark job created by the Stardog will have only one task with the same name as that of the job. For E.g., in case of Databricks, the task is visible under the job as shown:
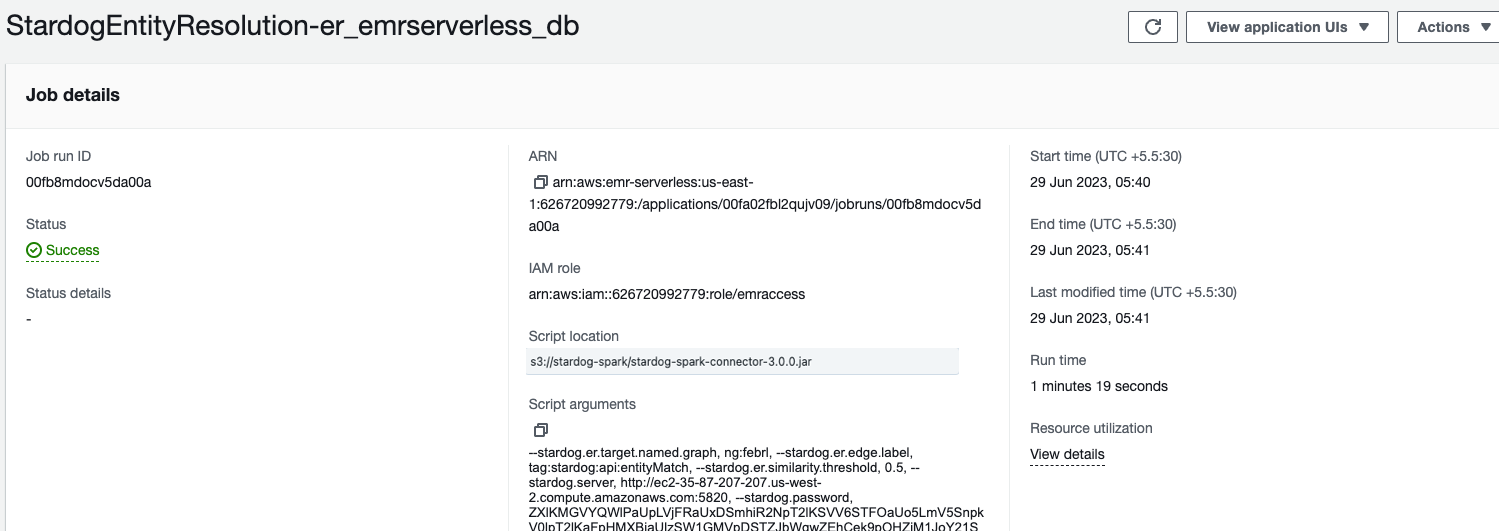
Similarly, the EMR Studio shows the entity resolution jobs. 
For Spark on Kubernetes, the job is submitted as a SparkApplication Custom Resource in the namespace declared in the template, named in the same Stardog<OperationName>-<Database><Timestamp> format. Inspect via kubectl:
$ kubectl get sparkapplications -n stardog-spark
NAME STATUS ATTEMPTS START FINISH AGE
StardogEntityResolution-MyDB11668700425701 COMPLETED 1 2026-05-19T03:14:01Z 2026-05-19T03:15:23Z 2m
$ kubectl logs -n stardog-spark <driver-pod-name>
Stardog converts the Entity Resolution configuration like database name, query, iri field name, target named graph and Stardog details into job parameters and passes these parameters to the Spark job at runtime.
List of job parameters:
| parameter name | Description |
|---|---|
| stardog.server | Stardog server URL from where external compute operation is triggered. The Spark job will connect back to this URL to write the results. |
| stardog.username | Stardog user who has triggered the external compute operation. Spark job will use this user name to authenticate into the Stardog server. |
| stardog.password | Auth token of the Stardog user who has triggered the external compute operation. Stardog encrypts this token while passing this parameter over a secured REST HTTPS call. The Spark job will use this auth token to authenticate into the Stardog server. |
| stardog.database | Stardog Database name. The Spark job will connect to this database to fetch the entities and write back the entity resolution results. |
| stardog.er.query | SPARQL query, which gets executed on Stardog. This query will fetch triples of the entity to resolve. |
| stardog.er.iri.field.name | IRI field name in the SPARQL query results represents the entity to resolve. |
| stardog.er.target.named.graph | The Spark job will write the entity resolution results to this named graph. |
| stardog.er.edge.label | Type of the edge. Spark job will create an edge of this type in the output to link the duplicate entities. If not provided, it will generate an edge of type tag:stardog:api:entityMatch. |
| stardog.er.include.score | Include the score in the entity resolution output. If not provided, the result will not include the score. |
| stardog.er.similarity.threshold | Two entities with a similarity score of more than this value will be considered duplicates. The value should be in the range of 0 to 1. |
| stardog.er.dataset.partition | Refer to spark-docs. Set this value to partition the dataset for ER pipeline. |