Virtual Graph Mappings
Learn how to unify relational data in Stardog at query time.
Page Contents
Background
In the Graph Data Model tutorial we looked at some example graph data about musicians and albums. For example, here’s part of the graph concerning The Beatles:
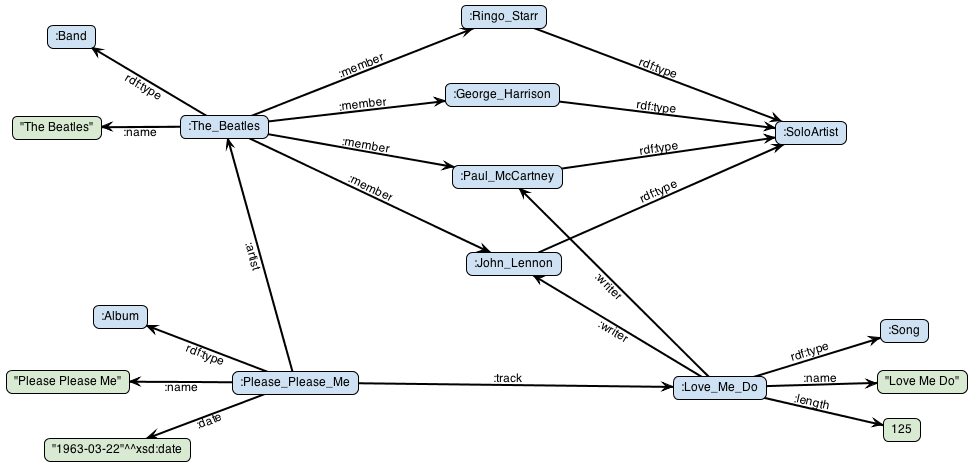
The focus of this tutorial is how we can populate some or all of a graph from a remote data source, i.e., from data that Stardog isn’t directly managing; in this case, from data stored in a relational database. We will be using the following relational schema in this tutorial:
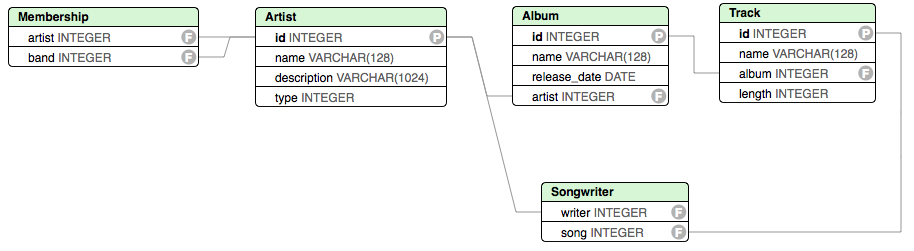
The example in this tutorial is inspired by the open music encyclopedia MusicBrainz database. The database schema for MusicBrainz is very complex for this tutorial, but for those interested in challenging real-world examples, you’ll find the LinkedBrainz mappings useful.
We will show you how to define the mappings from the relational schema to the graph model. These mappings are declarative: they describe the conceptual equivalences between the models but not the actual process of converting the relational data to a graph. When these mappings are loaded to Stardog the user can choose to materialize and store the graph in Stardog directly or to access the relational data as a virtual graph, i.e., at query time. For virtual graphs, Stardog will rewrite input SPARQL queries into SQL (or other needed source access languages) using the mappings, which expose the relational data as a graph without copying or duplicating the data.
The standard for mapping relational databases to RDF datasets is called R2RML: RDB to RDF Mapping Language. R2RML provides an RDF vocabulary to define the mappings as an RDF graph. In this tutorial we will describe the details of the R2RML mappings but use the more concise Stardog Mapping Syntax (SMS). SMS mappings can be automatically translated to R2RML and vice versa using stardog-admin virtual mappings -f <Mappings format>.
Mapping to Nodes
Generally, in the relational data model, each table represents one entity type, e.g. Artist, and the rows of that table represents instances of that type, e.g. The Beatles. In a typical mapping there is an RDFS class corresponding to each table and then each row is mapped to a node that is an instance of that type. There is also an RDF property corresponding to each column and the values of the row become nodes linked to the original node. Typically columns that are associated with foreign keys are mapped to IRIs whereas other columns are mapped to literals.
Before discussing the mappings in more detail, let’s look at the how the artist table mentioned in the above diagram looks:
| id | name | description | type |
|---|---|---|---|
| 1 | John Lennon | John Lennon (9 October 1940 – 8 December 1980) was an English singer and songwriter … | 1 |
| 2 | Paul McCartney | James Paul McCartney, (born 18 June 1942) is an English singer-songwriter, multi-instrumentalist, and composer … | 1 |
| 3 | Ringo Starr | Richard Starkey, (born 7 July 1940), known professionally as Ringo Starr, is an English musician, singer, songwriter and actor … | 1 |
| 4 | George Harrison | George Harrison (25 February 1943 – 29 November 2001) was an English guitarist, singer, songwriter, and music and film producer … | 1 |
| 5 | The Beatles | The Beatles were an English rock band formed in Liverpool in 1960 … | 2 |
Each row represents a musical artist that is either a band, indicated by the value 2 in the type column, or a person, indicated by the value 1 in the type column. Each row is uniquely identified by the id column and has columns that provide the name and the description of the artist.
Next is the table for albums:
| id | name | release_date | artist |
|---|---|---|---|
| 1 | Please Please Me | 1963-03-22 | 5 |
| 2 | McCartney | 1970-04-17 | 2 |
| 3 | Imagine | 1971-10-11 | 1 |
In this table we have the album IDs (unique to this table), name, release date, and a reference to the artist table indicating the artist that released the album.
The first step to define some mappings is to map the values from the table to RDF nodes.
Mapping IRIs
We will generate an Artist node in the graph for each row of the artist table and one Album node for each row of the album table. We need to generate IRIs for these nodes, and we need to do that in such a way that the IRI we chose won’t clash with any other IRI we generate in this dataset or any other IRI that we might later incorporate into this dataset. This can be achieved using IRI templates. An IRI template is like an rdf.html#IRIs[IRI] but refers to column names from the relational table by enclosing them in curly braces.
http://stardog.com/tutorial/Artist{id}
The IRI template is defined in the namespace http://stardog.com/tutorial/ to make sure it will not clash with IRIs generated by others. The prefix Artist in the local name is used to avoid clashes with IRIs we generate from other tables. The variable part of the template, {id}, will be replaced with the value of the id row for each row to ensure each row from this table gets a unique IRI. Based on this idea, the IRI template for the albums would look like this:
http://stardog.com/tutorial/Album{id}
There are no rules about IRI naming schemes and many other possible naming schemes can be used, including using a completely different namespace for each table or making the table name part of the IRI, etc.
An IRI template is primarily used to map a table’s row to an RDF subject but can also be used to map arbitrary columns to RDF objects. And multiple columns may be used in a template to ensure uniqueness. If the column value has characters that are not allowed in IRIs, e.g. spaces, the standard percent-encoding procedure is applied to generate an IRI-safe value.
Mapping Literals
Datatypes in relational databases can be mapped to corresponding RDF datatypes using the natural mapping of SQL values. For example, types like CHAR and VARCHAR are mapped to xsd:string whereas SMALLINT, INTEGER and BIGINT are mapped to xsd:integer.
In the SMS syntax a literal mapping is defined with column variables similar to IRI templates but enclosed within quotes like RDF triples. For example, the expression "{name}" represents the natural mapping of the name column to RDF.
It is also possible to override these datatypes by specifying a different datatype in the mapping, e.g. INTEGER column can be mapped to xsd:decimal or even xsd:double. For example, we can map the type column to decimal values with the expression "{type}"^^xsd:decimal.
Mapping to Triples
A triples map defines the mapping from one row of a relational table (or a SQL query) to RDF triples. Triples generated from a triples map all share the same subject.
Mapping Tables
In SMS, a triples map is written as a query to your data source followed by Turtle that maps that data to an RDF graph. The following is a triples map showing the mapping for the album table:
MAPPING :AlbumMapping
FROM SQL {
SELECT * FROM Album
}
TO {
?album a :Album ;
:name ?name ;
:artist ?artist ;
:date ?release_date
}
WHERE {
BIND(template("http://stardog.com/tutorial/Album{id}") AS ?album)
BIND(template("http://stardog.com/tutorial/Artist{artist}") AS ?artist)
};
The mapping begins with a SQL query to our database to get all of the data from the Album table which is contained within the FROM SQL block. Within the WHERE block, we BIND IRIs that we create to new variable names. We use the template function to define a template for the IRIs that we will create from these values. By placing id within curly braces, it pulls the value from the id column of our query and inserts it into our IRI. Once we define the IRIs, we BIND them AS a variable, in this case ?album and ?artist. These variables are then used along with the literals from our query withing the TO block of the mapping in order to define our RDF.
Mapping SQL Queries
Sometimes it is necessary to filter the rows of a table or apply transformations to the columns. For example, in the artist table we have types of the artists (band vs solo artist) encoded as integer values but we would like to map these to actual IRIs so that we can use those as the type of the node instead of a generic artist type for all nodes. In these cases, we can use a SQL query in the mappings.
There are several different SQL queries we can use to map the artists in our example. One way is to have different mappings to map the types of artists in separate mappings and have another mapping that applies to all artists for common properties:
MAPPING :SoloArtistMapping
FROM SQL {
SELECT * FROM Artist WHERE type = 1
}
TO {
?artist a :SoloArtist
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{id}") AS ?artist)
};
MAPPING :BandMapping
FROM SQL {
SELECT * FROM Artist WHERE type = 2
}
TO {
?artist a :Band
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{id}") AS ?artist)
};
MAPPING :ArtistMapping
FROM SQL {
SELECT * FROM Artist
}
TO {
?artist :name ?name ;
:description ?description
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{id}") AS ?artist)
};
Another way would be using a SQL query with a CASE statement in SQL to map the type column to an IRI.
Note that we are using the same IRI template for artists here as in the album mappings. Therfore the objects created by the albums mapping will be same as the subjects created here and the resulting graph will be connected as in the very first diagram.
Mapping Junction Tables
In a normalized relational schema, the conventional way to represent many-to-many relationships is by using junction tables, also known as bridge or associative tables. Unlike in regular tables, where a row represents one entity and its attributes, junction tables are used to represent relationships between entities defined in other tables.
The Member table shown in the schema previously is an example of a junction table and looks like this for The Beatles members.
It would be reasonable to include start and end dates in the membership table to differentiate current versus past memberships, but, to keep the examples in this tutorial simple, we are not doing that.
Excerpt from the Member table
| artist | band |
|---|---|
| 1 | 5 |
| 2 | 5 |
| 3 | 5 |
| 4 | 5 |
Mapping such a junction table to RDF is not any different than mapping other tables and can be done with a new triples map. In the RDF model above we have the member edge going from bands to people so we will use the artist column for the subject and the band column for the object:
MAPPING :MemberMapping
FROM SQL {
SELECT * FROM Membership
}
TO {
?band :member ?member
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{band}") AS ?band)
BIND(template("http://stardog.com/tutorial/Artist{artist}") AS ?member)
};
Note that, unlike previous mappings, there is no type associated with the subject since the artists mappings already provide the type for the subject.
Putting It Together
The full mappings for all the tables in our example look like this:
PREFIX : <http://stardog.com/tutorial/>
MAPPING :AlbumMapping
FROM SQL {
SELECT * FROM Album
}
TO {
?album a :Album ;
:name ?name ;
:artist ?artist ;
:date ?release_date
}
WHERE {
BIND(template("http://stardog.com/tutorial/Album{id}") AS ?album)
BIND(template("http://stardog.com/tutorial/Artist{artist}") AS ?artist)
};
MAPPING :ArtistMapping
FROM SQL {
SELECT * FROM Artist
}
TO {
?artist :name ?name ;
:description ?description
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{id}") AS ?artist)
};
MAPPING :SoloArtistMapping
FROM SQL {
SELECT * FROM Artist WHERE type = 1
}
TO {
?artist a :SoloArtist
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{id}") AS ?artist)
};
MAPPING :BandMapping
FROM SQL {
SELECT * FROM Artist WHERE type = 2
}
TO {
?artist a :Band
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{id}") AS ?artist)
};
MAPPING :MemberMapping
FROM SQL {
SELECT * FROM Membership
}
TO {
?band :member ?member
}
WHERE {
BIND(template("http://stardog.com/tutorial/Artist{band}") AS ?band)
BIND(template("http://stardog.com/tutorial/Artist{artist}") AS ?member)
};
MAPPING :SongMapping
FROM SQL {
SELECT * FROM Track
}
TO {
?song a :Song ;
:name ?name ;
:length ?length .
?album :track ?song .
}
WHERE {
BIND(template("http://stardog.com/tutorial/Song{id}") AS ?song)
BIND(template("http://stardog.com/tutorial/Album{album}") AS ?album)
};
MAPPING :SongwriterMapping
FROM SQL {
SELECT * FROM Songwriter
}
TO {
?song :writer ?writer
}
WHERE {
BIND(template("http://stardog.com/tutorial/Song{song}") AS ?song)
BIND(template("http://stardog.com/tutorial/Artist{writer}") AS ?writer)
}
Note that, for the Track table we created two different triples maps with different subjects. The reason is that the track property in our RDF model goes from albums to songs but the subject for the Track table is a Song.
R2RML Syntax
R2RML is the W3C standard for expressing mappings from relational databases to RDF datasets. In this tutorial, we have been using the SMS syntax for expressing these mappings but the concepts we described so far (IRI templates, triples maps, etc.) are based on the R2RML language.
The R2RML mappings are RDF graphs and written down in Turtle syntax. The SMS mappings can be translated to R2RML automatically. The following is the R2RML representation of the
prefix rr: <http://www.w3.org/ns/r2rml#>
prefix : <http://stardog.com/tutorial/>
prefix sm: <tag:stardog:api:mapping:>
:AlbumMapping
a rr:TriplesMap ;
rr:subjectMap [
rr:template "http://stardog.com/tutorial/Album{id}" ;
rr:class :Album
] ;
rr:predicateObjectMap [
rr:predicate :name ;
rr:objectMap [ rr:column "name" ]
] ;
rr:predicateObjectMap [
rr:predicate :date ;
rr:objectMap [ rr:column "release_date" ]
] ;
rr:predicateObjectMap [
rr:predicate :artist ;
rr:objectMap [ rr:template "http://stardog.com/tutorial/Artist{artist}" ]
] ;
rr:logicalTable [ rr:tableName "Album" ] .
In R2RML there is an explicit RDF node typed as a rr:TriplesMap for each triples map. Each triples map has exactly one rr:subjectMap providing the IRI template for the subject and optionally a rr:class triple specifying the type of the mapped node. In R2RML, there is a rr:predicateObjectMap triple that corresponds to each triple in SMS.
Full mappings in R2RML syntax is in the tutorials github repository. More information about R2RML syntax can be found in the R2RML specification.