Query Performance
Learn how to optimize graph queries in Stardog.
Page Contents
Background
At the core of Stardog lies the query optimizer whose mission is precisely to achieve optimal performance on every input query. The optimizer may rewrite a query into a form which is more efficient to execute but gives all the same answers. Sometimes, however, it may require a little help from the user to find the most efficient query execution plan.
Why Slow Queries Happen
-
the optimizer only performs transformations which preserve the semantics of the original query. It is possible, for example, to write a query whose result set explodes on any non-trivial database. There’s nothing that the optimizer can do about it (other than give insights through the query plan).
-
some datasets contain complex correlations which are not captured in statistics computed by Stardog and available to the query optimizer. It is generally infeasible to perfectly estimate selectivity for an arbitrary subset of a SPARQL query to plan it optimally.
-
statistics may be stale if the database is under constant write pressure. There’s the server option
index.statistics.update.automaticwhich governs when statistic should be re-computed after updates. However it’s possible that some update is not large enough to re-compute the statistics for the entire database but touches enough of the data to make the statistics inaccurate for a particular query. You can always force re-computation via thestardog-admin db optimizeCLI command. -
even if the statistics were always available for any subset of the query, it wouldn’t be possible to find the optimal plan in all cases and in reasonable time.
The Secret to Fast SPARQL Queries
So your query runs slower than acceptable; you’ve verified that it’s written as intended; and you cannot make it more specific. What now? Well, there’s no silver bullet. Don’t waste time or mental energy hunting for a silver bullet.
The following recipe is the secret heart of Stardog query optimization, which we’ve followed consistently for years.
For simplicity we restrict our attention to basic graph patterns (a.k.a. BGPs), i.e. sets of triple patterns.
- Begin with a naive version of the query, with all triple patterns in one scope.
- Run it. If it finishes in acceptable time, congrats, you’re done. 🎉
- If it doesn’t, we have to look at the plan to see what’s wrong. Often wrong means that there’s a group of triple patterns somewhere deep in the plan which matches a lot of results which need to be processed (e.g. sorted or added to a hashtable) for evaluation to go forward (see the section on pipeline breakers in the post about query plans).
- The only way to detect such patterns is to make an informed guess—after all, you know the data better than Stardog’s query planner at this point—and evaluate the guessed triple patterns in a separate query; best to do that with a
count(*)in projection instead ofSELECT *. - If the guess is wrong, make a different guess. Experience and domain knowledge help a lot. Repeat #5 as necessary—we said it was a secret but didn’t say it was magic.
- If the guess is right, re-formulate the original query such that the triples patterns in the problematic BGP are not joined together until late in the evaluation, i.e. near the root of the join tree. This can be done using sub-queries using the new query hint group.joins.
- Go to #2.
Let’s illustrate this on the following query which identifies deals made by an employee already involved in the same matter as a customer that’s listed in that deal.
This is a greatly simplified example of a typical query to detect potential frauds where the data has hidden relations between people involved in the deal. Typically such queries have many BGPs (sometimes dozens of triple patterns) and it’s not as easy to identify the problematic parts, but the general idea remains the same.
SELECT * WHERE {
?deal a :Deal ;
:employee ?employee ;
:customer ?customer .
?employee :name ?employeeName ;
:involvedAsEmployee ?matter .
?customer :name ?customerName ;
:involvedAsCustomer ?matter .
}
If we look at the graphical representation of this query, we’ll see the following diamond structure:
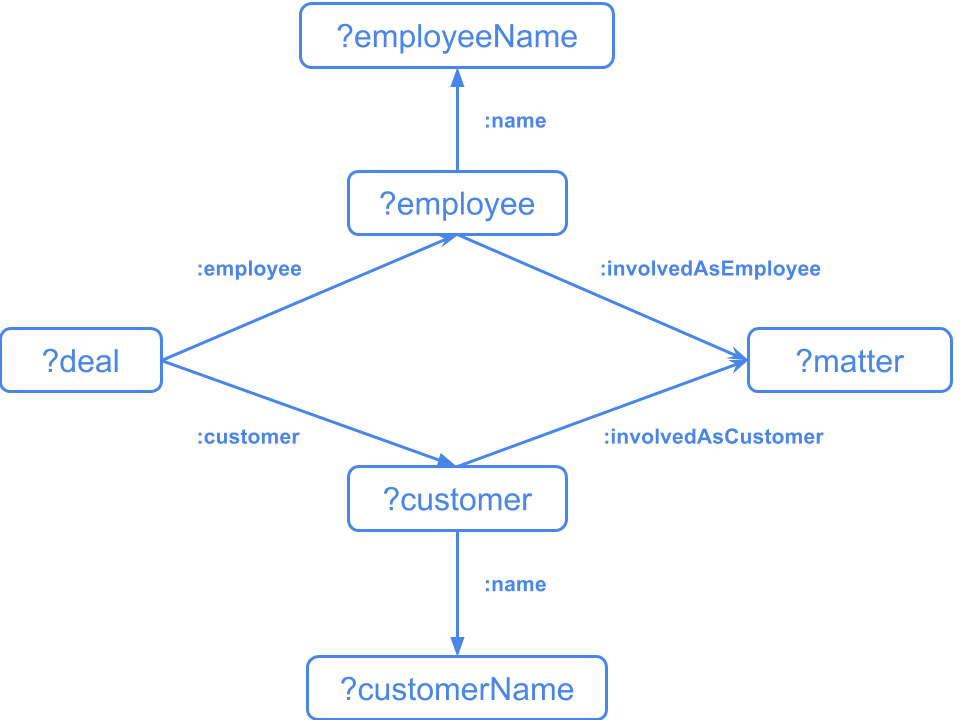
Stardog’s optimizer will detect that the :name relation is functional, which means the joins with the patterns ?employee :name ?employeeName and ?customer :name ?custName should not create trouble.
The key planning question here is which join—on the ?deal or the ?matter—should be evaluated first? The answer depends on the data: if the deal join is selective it should be done first, or if few people were involved in the same matter, the matter join should be done first.
This is exactly the kind of decision-making that the optimizer is responsible for. In the ideal world, it’ll decide based on statistics and will decide correctly. We don’t live in the ideal world, though, so in some situations (outdated statistics or complex inter-dependencies in the data) it can make a wrong choice.
The deal join is a join on the subject variable while the matter join is a join on the object variable. Stardog has better statistics about the former because star-shaped n-ary join queries are common.
So it’s possible that there are many deals and the optimizer decides to first find people which were involved in the same matter, but it turns out that some matters in the past involved many people. So that join is not selective and the optimizer made a wrong choice. We’re now at the step 3 of the algorithm above.
First, let’s look at the query plan:
Projection(?deal, ?employee, ?customer, ?employeeName, ?custName, ?matter) [#500]
`─ MergeJoin(?customer) [500]
+─ MergeJoin(?customer) [#1000]
│ +─ Sort(?customer) [#1000]
│ │ `─ MergeJoin(?matter) [#1000]
│ │ +─ Scan[POSC](?customer, :involvedAsCustomer, ?matter) [#100000]
│ │ `─ Scan[POSC](?employee, :involvedAsEmployee, ?matter) [#100000]
│ `─ Scan[PSOC](?customer, :name, ?customerName) [#1000000]
`─ Sort(?customer) [#1000000]
`─ MergeJoin(?employee) [#1000000]
+─ Sort(?employee) [#1000000]
│ `─ NaryJoin(?deal) [#1000000]
│ +─ Scan[POSC](?deal, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>, :Deal) [#1000000]
│ +─ Scan[PSOC](?deal, :customer, ?customer) [#1000000]
│ `─ Scan[PSOC](?deal, :employee, ?employee) [#1000000]
`─ Scan[PSOC](?employee, :name, ?employeeName) [#1000000]
We can see that the results of the join on ?matter are sorted (in memory, with possible spilling to disk) because the optimizer thinks there are only around 1000 solutions to sort. This looks like a potential culprit behind poor performance. We can test this hypothesis by running this join in a dedicated query (step 4):
SELECT (count(*) as ?count)
WHERE {
?employee :involvedAsEmployee ?matter .
?customer :involvedAsCustomer ?matter .
}
Running a query with count(*) is typically faster than retrieving all bindings sets and counting them on the client side.
When this returns a lot of results, we know it’s a performance problem. The question is whether it returns, say, an order of magnitude more results than the estimation in the original plan. If this is the case, the optimizer made its join order choice based on inaccurate information and there may be a better plan in which this join is deferred. Assuming that’s what we see, we move to #6 (otherwise we look at other potentially problematic joins in the plan and test them separately).
Step 6—tearing apart problematic queries—is where query hints in Stardog 5 make your life easier. In earlier versions of Stardog, you’d have to put the two patterns above in different subqueries but now the group.joins hint will suffice:
SELECT * WHERE {
{ #pragma group.joins
?deal :employee ?employee .
?employee :name ?employeeName ;
:involvedAsEmployee ?matter .
}
{ #pragma group.joins
?deal :customer ?customer .
?customer :name ?custName ;
:involvedAsCustomer ?matter .
}
?deal a :Deal .
}
This hint tells the optimizer to first compute the join trees for the respective scopes (three patterns in each) and only then join them together. There are two reasons the query can now run faster: first, not all people involved in some earlier matters may co-occur in deals (as customers or employees); second, now the join is on two variables (?deal and ?matter) which gives the query engine extra opportunities to prune intermediate results.
Be warned not to introduce disconnected scopes in this way, i.e. it should be possible to create a join tree where each join has a join condition (i.e. a shared variable between two patterns). If not—that is, if a scope has two or more disconnected groups of patterns—evaluation would have to compute their Cartesian product, which is typically slow. Cartesian products are computed using loop joins so keep an eye out for those generally.
Write Specific Queries
While analytic queries are indispensable to some applications, others often require running specific queries which fetch information related to particular nodes in the graph. Such queries are typically much easier for Stardog since it can quickly filter our irrelevant information by pushing the selective patterns deep into the plan and evaluating them early in the execution. It is almost always better to include selective patterns in the query rather than doing filtering on the client side.
There are at least four simple ways to make a query specific:
- Use parameterized queries with the SNARL API. Stardog will then safely replace the variable occurrences in the query plan but will preserve the variable name in the result set.
- Use the
VALUES ?var { :x :y ... }construct in SPARQL to statically bind the variable to a constant. - Use the
BIND(:x as ?var)construct (but make sure to put this before any other occurrence of?varin the same scope). - Use
FILTER(?var = :x)orFILTER(?var IN :x, :y, ...)but keep in mind the subtle difference between equality and identity discussed above.
Stardog includes optimizations to push such selective patterns into nested scopes, e.g. unions, so there is generally no need to manually work through all occurrences of a variable to bind it to a constant.