Cache Management
This page discusses using a distributed cache in Stardog to boost performance for a variety of use cases.
Page Contents
Overview
A set of cached datasets for virtual graphs can be run in conjunction with a Stardog server or cluster. This feature gives users the following abilities:
Reduce Load on Upstream Database Servers
When using virtual graphs, it can be the case that the upstream server is slow, overworked, far away, or lacks operational capacity. This feature addresses this by allowing operators to create a cached dataset running in its own node. In this way, the upstream database can be largely avoided, and cache refreshes can be scheduled manually using the cache refresh command for times when its workload is lighter.
Partial Materialization of Slowly Changing Data
A cached dataset can be created for a virtual graph that maps to a portion of a database that does not update frequently. That dataset is used in conjunction with another uncached virtual graph mapped to the portions of the database that updates more frequently. This hybrid approach can be used to balance performance and freshness.
For horizontal read scalability of Stardog Cluster we recommend read replicas instead of distributed cache targets.
Architecture
Running inside of a Stardog server (either a cluster or single node) is a component called the cache manager. The cache manager is responsible for tracking what caches exist, where they are, and what is in them. The query planner must work with the cache manager to determine whether or not it can use a cache in the plan.
A cache is only created for a specific virtual graph (and data source) configuration. Caches are not automatically invalidated. If the user changes the configuration of the virtual graph (e.g. mappings) or underlying data source, then the user will need to drop the cache and recreate it for the new configuration, otherwise query results may contain data from the invalid cache.
Cache Targets
Cache targets are separate processes that look a lot like a single-node Stardog server on the inside. They contain a single database into which cached information is loaded and updated. Many caches can be on a single cache target. How to balance them is up to each operator as they consider their own resource and locality needs.
Though cache targets expose most Stardog functionality, we recommend operators do not use cache targets for other purposes. Stardog servers that are started as cache targets should only serve as cache nodes to minimize the risk of conflicts with general-purpose use of the server.
The following diagram shows how the distributed cache can be used to answer queries, where some of the data is cached, and some remains in its original source.
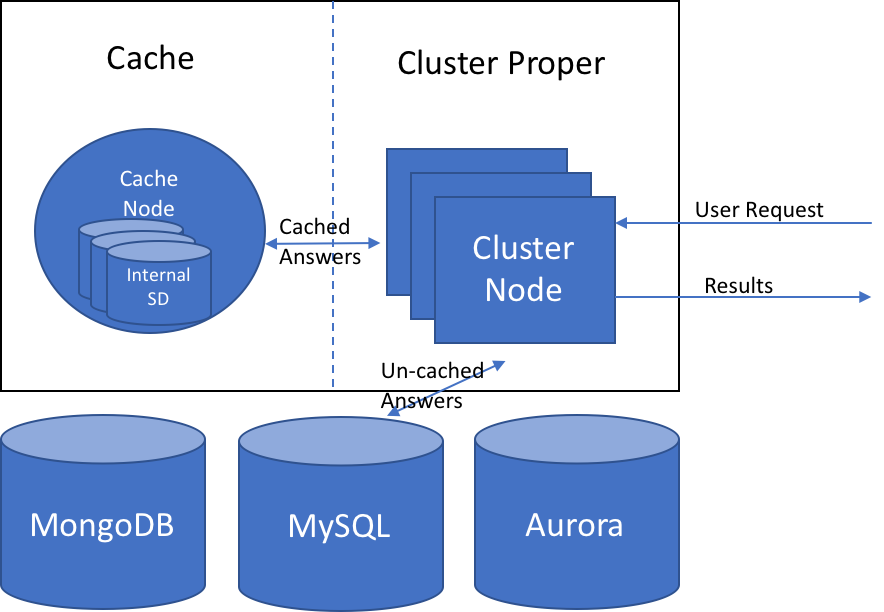
Setting Up A Distributed Cache
To set up Stardog with a distributed cache, first start a Stardog server as described in Administering Stardog.
A cache node/target should be the same Stardog version as the cluster (or server) it is serving.
For every cache target needed, another Stardog server must be run. Stardog servers are configured to be cache targets with the following options in the stardog.properties:
# Flag to run this server as a cache target
cache.target.enabled=true
Once both Stardog and the cache target are running, we need to register the cache target with Stardog. That is done with the cache target command:
$ stardog-admin --server http://<cluster IP>:5820 cache target add <target name> <target hostname>:5820 admin <admin pw>
Once Stardog knows of the existing cache target, datasets can be cached on it. To cache a graph, run a cache create command similar to the following:
$ stardog-admin --server http://<cluster ip>:5820 cache create cache://cache1 --graph virtual://dataset --target ctarget --database movies
This will create a cache named cache://cache1, which will hold the contents of the virtual graph virtual://dataset, which is associated with the database movies and store that cache on the target ctarget.
When the data changes on the underlying source system, you can use the cache refresh command to sync data between the source and update the cache target. However, this command will not handle configuration changes, such as new mappings or data source configuration updates. If those items change, you need to drop the cache and create a new one.
Known Issues and Limitations
- Caches are not automatically invalidated if the configuration of the virtual graph or underlying data source change (e.g. mappings or connection information). The cache must be dropped and recreated by the user.
- Cache targets that run as separate Stardog processes can only be used with Stardog Cluster. A single node Stardog instance cannot use a separate standalone cache target.
- Cache targets do not prevent authorized users from using the Stardog server for other purposes. This can have unintended consequences when used in conjunction with caching. For example, a user could add a data source to the cache target for one relational database system, then add another data source with the same name to the cluster. If the user then attempts to cache a virtual graph the data sources will conflict, preventing the cache from being created. We recommend Stardog servers that are running as cache targets only be used for caching, which is managed by Stardog itself.