GraphQL
This page discusses Stardog’s support for querying data using GraphQL.
Page Contents
Overview
Stardog supports querying data stored (or mapped) in a Stardog database using GraphQL queries. You can load data into Stardog as usual and execute GraphQL queries without creating a GraphQL schema. You can also associate one or more GraphQL schemas with a database and execute GraphQL queries against one of those schemas.
The following table shows the correspondence between RDF concepts and GraphQL:
| RDF | GraphQL |
|---|---|
| Node | Object |
| Class | Type |
| Property | Field |
| Literal | Scalar |
Execution of GraphQL queries in Stardog does not follow the procedural rules defined in the GraphQL spec.
Instead Stardog translates GraphQL queries to SPARQL and then SPARQL results to GraphQL results based on the correspondences shown in the preceding table. Each RDF node represents a GraphQL object. Properties of the node are the fields of the object with the exception of rdf:type property which represents the type of the object. Literals in RDF are mapped to GraphQL scalars.
| RDF | GraphQL |
|---|---|
xsd:integer | IntValue |
xsd:float | FloatValue |
xsd:string | StringValue |
xsd:boolean | BooleanValue |
UNDEF | NullValue |
IRI | EnumValue |
In the following sections we will use a slightly modified version of the canonical GraphQL Star Wars example to explain how GraphQL queries work in Stardog. The following graph shows the core elements of the dataset and links between those nodes:
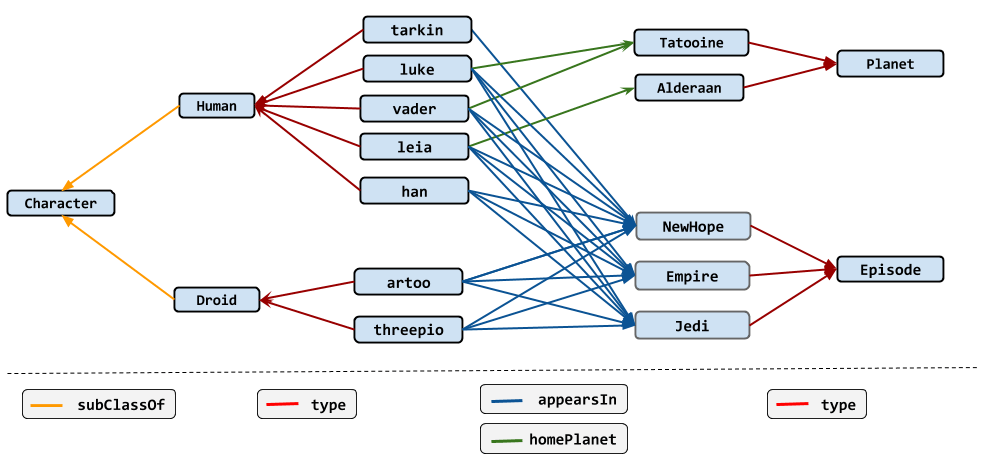
The full dataset in Turtle format is available in the examples repo.
Executing GraphQL Queries
GraphQL queries can be run via the CLI, the Java API, or the HTTP API.
The GraphQL CLI graphql execute command can be executed by providing a query string:
$ stardog graphql execute starwars "{ Human { name }}"
or a file containing the query:
$ stardog graphql execute starwars query.file
The --reasoning flag can be used with the CLI command to enable reasoning.
The HTTP command can be used to execute GraphQL queries. The endpoint for GraphQL queries is http://HOST:PORT/{db}/graphql. The following command uses curl to execute a GraphQL query:
$ curl -G -vsku admin:admin --data-urlencode query="{ Human { name }}" localhost:5820/starwars/graphql
Reasoning can be enabled by setting a special variable @reasoning in the GraphQL query variables.
Any standard GraphQL client, like GraphiQL, can be used with Stardog:
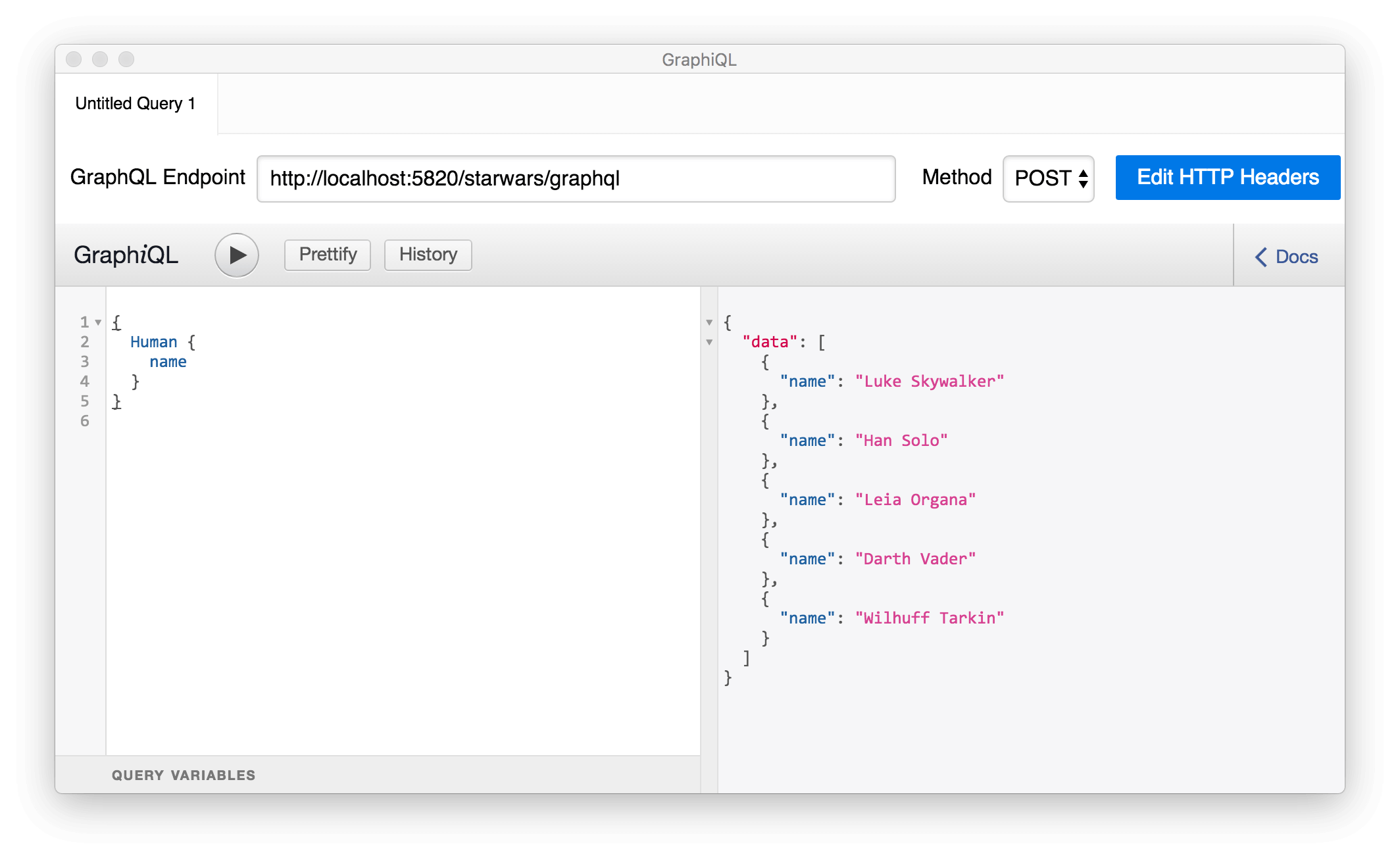
Stardog by default uses HTTP basic access authentication. In order to use GraphiQL with Stardog you either need to start the Stardog server with --disable-security option so it won’t require credentials or set the HTTP header Authorization in the request. If the default credentials admin/admin are being used in non-production settings, the HTTP header Authorization may be set to the value Basic YWRtaW46YWRtaW4= in the GraphiQL UI. The curl example above can be used to see the correct value of the header for your credentials.
Fields and Selection Sets
A top-level element in GraphQL by default represents a type and will return all the nodes with that type. The fields in the query will return matching properties:
Query
{
Human {
name
}
}
Result
{
"data" : [ {
"name" : "Luke Skywalker"
}, {
"name" : "Han Solo"
}, {
"name" : "Leia Organa"
}, {
"name" : "Darth Vader"
}, {
"name" : "Wilhuff Tarkin"
} ]
}
Each field in the query is treated as a required property of the node (unless an @optional directive is used) so any node without corresponding properties will not appear in the results:
Query
{
Human {
name
homePlanet
}
}
Result
{
"data" : [ {
"name" : "Luke Skywalker",
"homePlanet" : "Tatooine"
}, {
"name" : "Leia Organa",
"homePlanet" : "Alderaan"
}, {
"name" : "Darth Vader",
"homePlanet" : "Tatooine"
} ]
}
If a node in the graph has multiple properties, then in the query results those results will be returned as an array:
Query
{
Droid {
name
friends
}
}
Result
{
"data" : [ {
"name" : "C-3PO",
"friends" : [ "luke", "han", "leia", "artoo" ]
}, {
"name" : "R2-D2",
"friends" : [ "luke", "han", "leia" ]
} ]
}
Also note that Stardog does not enforce the GraphQL requirement that leaf fields must be scalars. In the previous example friends of a droid are objects but the query does not provide any fields. In those cases, the identifier of the node will be returned as a string.
Arguments
In GraphQL fields are, conceptually, functions which return values and may accept arguments that alter their behavior. Arguments have no predefined semantics but the typical usage is for defining lookup values for fields. Stardog adopts this usage and treats arguments as filters for the query. The following query return only the node whose id field is 1000:
Query
{
Human(id: 1000) {
id
name
homePlanet
}
}
Result
{
"data": {
"name": "Luke Skywalker",
"id": 1000,
"homePlanet": "Tatooine"
}
}
Arrays can be used to specify multiple values for a field in which case nodes matching any field will be returned:
Query
{
Human(id: [1000, 1003]) {
id
name
homePlanet
}
}
Result
{
"data": [
{
"name": "Luke Skywalker",
"id": 1000,
"homePlanet": "Tatooine"
},
{
"name": "Leia Organa",
"id": 1003,
"homePlanet": "Alderaan"
}
]
}
Reasoning
GraphQL queries by default only return results based on explicit nodes and edges in the graph.
- Reasoning may be enabled in the usual ways to run queries with inferred nodes and edges, e.g. to perform type inheritance
- In the example graph,
HumanandDroidare defined as subclasses of theCharacterclass. The following query will return no results without reasoning but when reasoning is enabledCharacterwill act like a GraphQL interface and the query will return both humans and droids:
Query
{
Character {
name
}
}
Query Variables
{
"@reasoning": true
}
Result
{
"data" : [ {
"name" : "Luke Skywalker"
}, {
"name" : "Han Solo"
}, {
"name" : "Leia Organa"
}, {
"name" : "C-3PO"
}, {
"name" : "R2-D2"
}, {
"name" : "Darth Vader"
}, {
"name" : "Wilhuff Tarkin"
} ]
}
Fragments
Stardog supports GraphQL fragments (both inline or via fragment definitions). This query shows how fragments can be combined with reasoning to select different fields for subtypes:
Query
{
Character {
name
... on Human {
friends
}
... on Droid {
primaryFunction
}
}
}
Result
{
"data" : [ {
"name" : "Luke Skywalker",
"friends" : [ "threepio", "artoo", "han", "leia" ]
}, {
"name" : "Han Solo",
"friends" : [ "leia", "artoo", "luke" ]
}, {
"name" : "Leia Organa",
"friends" : [ "threepio", "artoo", "luke", "han" ]
}, {
"name" : "C-3PO",
"primaryFunction" : "Protocol"
}, {
"name" : "R2-D2",
"primaryFunction" : "Astromech"
}, {
"name" : "Darth Vader",
"friends" : "tarkin"
}, {
"name" : "Wilhuff Tarkin",
"friends" : "vader"
} ]
}
Aliases
By default, the key in the response object will use the field name queried. However, you can define a different name by specifying an alias. The following query renames both of the fields in the query:
Query
{
Human {
fullName: name
bornIn: homePlanet
}
}
Result
{
"data": [
{
"fullName": "Luke Skywalker",
"bornIn": "Tatooine"
},
{
"fullName": "Leia Organa",
"bornIn": "Alderaan"
},
{
"fullName": "Darth Vader",
"bornIn": "Tatooine"
}
]
}
Variables
A GraphQL query can be parameterized with variables which must be defined at the top of an operation. Variables are in scope throughout the execution of that operation. A value should be provided for GraphQL variables before execution or an error will occur. The following query will return a single result when executed with the input {"id": 1000}:
Query
query getHuman($id: Integer) {
Human(id: $id) {
id
name
}
}
Query Variables
{
"id": 1000
}
Result
{
"data": {
"name": "Luke Skywalker",
"id": 1000
}
}
Ordering Results
The results of GraphQL queries may be randomly ordered. A special argument orderBy can be used at the top level to specify which field to use for ordering the results. The following query uses the values of the name field for ordering the results:
Query
{
Human(orderBy: name) {
name
}
}
Results
{
"data": [
{ "name": "Darth Vader" },
{ "name": "Han Solo" },
{ "name": "Leia Organa" },
{ "name": "Luke Skywalker" },
{ "name": "Wilhuff Tarkin" }
]
}
The results are ordered in ascending order by default. We can sort results in descending order as follows:
Query
{
Human(orderBy: {field: name, desc: true}) {
name
}
}
Result
{
"data": [
{ "name": "Wilhuff Tarkin" },
{ "name": "Luke Skywalker" },
{ "name": "Leia Organa" },
{ "name": "Han Solo" },
{ "name": "Darth Vader" }
]
}
Multiple ordering criteria can be used:
Query
{
Human(orderBy: [homePlanet,
{field: name, desc: false}]) {
name
homePlanet @optional
}
}
Result
{
"data": [
{ "name": "Wilhuff Tarkin" },
{ "name": "Han Solo" },
{ "name": "Leia Organa",
"homePlanet": "Alderaan" },
{ "name": "Luke Skywalker",
"homePlanet": "Tatooine" },
{ "name": "Darth Vader",
"homePlanet": "Tatooine" }
]
}
We first use the homePlanet field for ordering and the results with no home planet come up first. If two results have the same value for the first order criteria, e.g. Luke Skywalker and Darth Vader, then the second criteria is used for ordering.
Paging Results
Paging through the GraphQL results is accomplished with first and skip arguments used at the top level. The following query returns the first three results:
Query
{
Human(orderBy: name, first: 3) {
name
}
}
Results
{
"data": [
{ "name": "Darth Vader" },
{ "name": "Han Solo" },
{ "name": "Leia Organa" }
]
}
The following query skips the first result and returns the next two results:
Query
{
Human(orderBy: name, skip:1, first: 2) {
name
}
}
Result
{
"data": [
{ "name": "Han Solo" },
{ "name": "Leia Organa" }
]
}
Directives
Directives provide a way to describe alternate runtime execution and type validation behavior in GraphQL. The spec defines two built-in directives: @skip and @include. Stardog supports both directives and introduces several others.
@skip(if: EXPR)
The skip directive includes a field value in the result conditionally. If the provided expression evaluates to true the field will not be included. Stardog allows arbitrary SPARQL Expressions to be used as the conditions. Any of the supported SPARQL Query Functions can be used in these expressions. The expression can refer to any field in the same selection set and is not limited to the field directive is attached to. The following query returns the name field only if the name does not start with the letter L:
Query
{
Human {
id
name @skip(if: "strstarts($name, 'L')")
}
}
Result
{
"data": [
{
"id": 1000
},
{
"name": "Han Solo",
"id": 1002
},
{
"id": 1003
},
{
"name": "Darth Vader",
"id": 1001
},
{
"name": "Wilhuff Tarkin",
"id": 1004
}
]
}
@include(if: EXPR)
The @include directive works negation of the @skip directive; that is, the field is included only if the expression evaluates to true. We can use Variables inside the conditions, too. The following example executed with input {"withFriends": false} will not include friends in the results:
Query
query HumanAndFriends($withFriends: Boolean) {
Human @type {
name
friends @include(if: $withFriends) {
name
}
}
}
Query Variables
{
"withFriends": false
}
Result
{
"data": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
},
{
"name": "Darth Vader"
},
{
"name": "Wilhuff Tarkin"
}
]
}
@filter(if: EXPR)
The @filter directive looks similar to @skip and @include but filters the whole object instead of just a single field. In that regard it works more like Arguments but arbitrary expressions can be used to select specific nodes. The next query returns all humans whose id is less than 1003:
Query
{
Human {
name
id @filter(if: "$id < 1003")
}
}
Result
{
"data": [
{
"name": "Luke Skywalker",
"id": 1000
},
{
"name": "Han Solo",
"id": 1002
},
{
"name": "Darth Vader",
"id": 1001
}
]
}
Unlike the previous two filters it doesn’t matter which field the @filter directive is syntactically adjacent to since it applies to the whole selection set.
@optional
Stardog treats every field as required by default and will not return any nodes if they don’t have a matching value for the fields in the selection set. The @optional directive can be used to mark a field as optional. The following query returns the home planets for humans if it exists but skips that field if it doesn’t:
Query
{
Human {
name
homePlanet @optional
}
}
Result
{
"data": [
{
"name": "Luke Skywalker",
"homePlanet": "Tatooine"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa",
"homePlanet": "Alderaan"
},
{
"name": "Darth Vader",
"homePlanet": "Tatooine"
},
{
"name": "Wilhuff Tarkin"
}
]
}
@type
By default every field in the GraphQL query other than the topmost field represents a property in the graph. Sometimes we might want to filter some nodes based on their types; that is, based on the values of the special built-in property rdf:type. Stardog provides a directive as a shortcut for this purpose. The following query returns only the droid friends of humans because the Droid field is marked with the @type directive:
Query
{
Human {
name
friends {
Droid @type
name
}
}
}
Result
{
"data": [
{
"name": "Luke Skywalker",
"friends": [
{
"name": "R2-D2"
},
{
"name": "C-3PO"
}
]
},
{
"name": "Han Solo",
"friends": {
"name": "R2-D2"
}
},
{
"name": "Leia Organa",
"friends": [
{
"name": "R2-D2"
},
{
"name": "C-3PO"
}
]
}
]
}
@bind(to: EXPR)
Fields bind to properties in the graph but it is also possible to have fields with computed values. When @bind directive is used for a field the value of that field will be compared by evaluating the given SPARQL expression. The following example splits the name field on a space to compute firstName and lastName fields:
Query
{
Human {
name @hide
firstName @bind(to: "strbefore($name, ' ')")
lastName @bind(to: "strafter($name, ' ')")
}
}
Result
{
"data": [
{
"firstName": "Luke",
"lastName": "Skywalker"
},
{
"firstName": "Han",
"lastName": "Solo"
},
{
"firstName": "Leia",
"lastName": "Organa"
},
{
"firstName": "Darth",
"lastName": "Vader"
},
{
"firstName": "Wilhuff",
"lastName": "Tarkin"
}
]
}
@hide
Query results can be flattened using the @hide directive. For example, in our data characters are linked to episode instances that have an index property. The following query retrieves the episode indexes but, by hiding the intermediate episode instances, humans are directly linked to the episode index:
Query
{
Human {
name
appearsIn @hide {
episodes: index
}
}
}
Result
{
"data": [
{
"name": "Luke Skywalker",
"episodes": [4, 5, 6]
},
{
"name": "Han Solo",
"episodes": [4, 5, 6]
},
{
"name": "Leia Organa",
"episodes": [4, 5, 6]
},
{
"name": "Darth Vader",
"episodes": [4, 5, 6]
},
{
"name": "Wilhuff Tarkin",
"episodes": 4
}
]
}
@lang
By default, GraphQL queries in Stardog match string literals without language tags. The @lang directive can be used to include language-tagged string literals as well. Assuming the example data is modified so that some character names are language-tagged, the following query will return them, as well as names without language tags:
Query
{
Human {
name @lang
}
}
Result
{
"data" : [ {
"name" : "Luke Skywalker"
}, {
"name" : "Han Solo@en-us"
}, {
"name" : "Leia Organa"
}, {
"name" : "Dark Vador@fr"
}, {
"name" : "Wilhuff Tarkin"
} ]
}
@hint
Staring with version 11.2, Stardog supports preamble query hints in GraphQL via @hint directive (scope hints are not yet supported).
@hint directive accepts one argument, value, which can be either a single hint definition or a list of definitions, each definition expressed as a name=value pair. The name must refer to one of the supported hints), otherwise the SPARQL engine will report an error.
For example:
query withMultipleHints @hint(value: ["join.hash=off", "plan.cache=off"]) {
Human {
name
}
}
or:
query withSingleHint @hint(value: "join.sortMerge=off") {
Human {
name,
homePlanet { region, system }
}
}
Namespaces in GraphQL
RDF uses IRIs as identifiers whereas in GraphQL we have simple names as identifiers. The examples so far use a single default namespace where names in GraphQL are treated as local names in that namespace. If a Stardog graph uses multiple namespaces, then it is possible to use them in GraphQL queries in several different ways.
If there are stored namespaces in the database then the associated prefixes can be used in the queries. For example, suppose we have the prefix foaf associated with the namespace http://xmlns.com/foaf/0.1/ in the database. In SPARQL the prefixed name foaf:Person would be used for the IRI http://xmlns.com/foaf/0.1/Person. In GraphQL, the : character cannot be used in field names so instead Stardog uses the _ character: the prefixed name here would be foaf_Person. The query using FOAF namespace would look like this:
{
foaf_Person {
foaf_name
foaf_mbox
}
}
If the namespace is not stored in the database an inline prefix definition can be provided with the @prefix directive:
query withPrefixes @prefix(foaf: "http://xmlns.com/foaf/0.1/") {
foaf_Person {
foaf_name
foaf_mbox
}
}
Sometimes field names might use the underscore character and it might not indicate a prefix. To differentiate two cases Stardog looks at the prefix before the underscore and checks if it is defined in the query or if it is stored in the database. In some cases the IRI local name might be using characters like - that is not allowed in GraphQL names. In those cases an alias can be defined to map a field name to an IRI. These aliases are defined in a @config directive at the query level as follows:
query withAliases @config(alias: {myType: "http://example.com/my-type",
myProp: "http://example.com/my-prop"})
{
myType {
myProp
}
}
Named Graphs in GraphQL
GraphQL queries by default are evaluated over the union of all graphs stored in the Stardog database. It is possible to limit the scope of the query to one or more specific named graphs. Suppose we partition the Star Wars dataset by moving instances of each type to a different named graph using the following SPARQL update query:
DELETE { ?s ?p ?o }
INSERT { GRAPH ?type { ?s ?p ?o } }
WHERE { ?s a ?type ; ?p ?o }
The following queries (with reasoning) will return 5 humans, 2 droids and all 7 characters respectively:
Query
query onlyHumanGraph @config(graph: Human) {
Character {
name
}
}
Result
{
"data": [
{ "name": "Luke Skywalker" },
{ "name": "Han Solo" },
{ "name": "Leia Organa" },
{ "name": "Darth Vader" },
{ "name": "Wilhuff Tarkin" }
]
}
Query
query onlyDroidGraph @config(graph: Droid) {
Character {
name
}
}
Result
{
"data": [
{ "name": "C-3PO" },
{ "name": "R2-D2" }
]
}
Query
query bothGraphs @config(graph: [Human, Droid]) {
Character {
name
}
}
Result
{
"data": [
{ "name": "Luke Skywalker" },
{ "name": "Han Solo" },
{ "name": "Leia Organa" },
{ "name": "C-3PO" },
{ "name": "R2-D2" },
{ "name": "Darth Vader" },
{ "name": "Wilhuff Tarkin" }
]
}
GraphQL Schemas
GraphQL is a strongly-typed language where the fields used in a query should conform to the type definitions in a GraphQL schema. By default, Stardog relaxes this restriction and allows queries to be executed without an explicit schema. However, if desired, one or more GraphQL schemas can be added to the database and used during query execution. The benefits of using an explicit schema are as follows:
- Queries will be validated with strict typing
- Default translation of RDF values to GraphQL values can be overridden
- Only the parts of the graph defined in the schema will be exposed to the user
A GraphQL schema can be created and registered manually or a default GraphQL schema can be generated automatically from the RDFS/OWL schema or SHACL constraints defined in the database as explained in the next sections.
Manually registered GraphQL schemas
Here is an example schema that can be used with the Star Wars dataset:
schema {
query: QueryType
}
type QueryType {
Character: Character
Human(id: Int, first: Int, skip: Int, orderBy: ID): Human
Droid(id: Int): Droid
}
interface Character {
id: Int!
name: String!
friends(id: Int): [Character]
appearsIn: [Episode]
}
type Human implements Character {
iri: ID!
id: Int!
name: String!
friends(id: Int): [Character]
appearsIn: [Episode]
}
type Droid implements Character {
id: Int!
name: String!
friends(id: Int): [Character]
appearsIn: [Episode]
primaryFunction: String
}
type Episode {
index: Int!
name: String!
}
Each GraphQL schema defines a query type which specifies the top-level field that can be used in a query. In Stardog the query type is simply an enumeration of classes in the database that we want to expose in queries. For example, the schema defines the Episode type but does not list it under QueryType which means you cannot query for episodes directly.
Note that, without a schema each top-level type can have various built-in arguments like first or skip. In this schema we chose to define them for the Human type but not for others. This means a query like { Droid(first: 1) { name } } will be invalid with respect to this schema and rejected even though it is valid if executed without a schema.
This schema can be added to the database by giving it a name:
$ stardog graphql schema --add characters starwars characters.graphqls
Added schema characters
We can then execute the query by specifying the schema name along with the query:
$ stardog graphql execute --schema characters starwars "{ Human { name friends { name } } }"
When a schema is specified for a query it gets added to the query parameters using a special variable named @schema. When using the HTTP API directly this variable can be set to choose the schema for a query by sending the query variable {"schema": "characters" }.
Query
{
Human(id: 1004) {
name
friends {
name
}
}
}
Query Variables
{
"@schema": "characters"
}
Result
{
"data": [
{
"name": "Wilhuff Tarkin",
"friends": [
{
"name": "Darth Vader"
}
]
}
]
}
Note that the friends field in the result is an array value due to the corresponding definition in the schema. This query executed with a schema would return the single object value for the field.
An important point about schemas is that the types defined in the schema do not filter the query results. For example, we can define a much simpler humans schema against the Star Wars dataset:
schema {
query: QueryType
}
type QueryType {
Human(id: [Int]): Human
}
type Human {
id: Int!
name: String!
friends: [Human]
}
This query allows only Human instances to be queried at the top level and declares that the friend of each Human is also a Human. This schema definition is incompatible with the data since humans have droid friends. Stardog does not check if the schema is correct with respect to the data and will not enforce type restrictions in the results. So if we ask for the friends of a human, then the droids will also be returned in the results:
Query
{
Human(id: 1000) {
name
friends {
name
}
}
}
Query Variables
{ "@schema": "humans" }
Result
{
"data": [
{
"name": "Luke Skywalker",
"friends": [
{ "name": "Han Solo" },
{ "name": "Leia Organa" },
{ "name": "C-3PO" },
{ "name": "R2-D2" }
]
}
]
}
Auto-generated GraphQL schemas
When the option graphql.auto.schema is set to true in the database configuration a default GraphQL schema will be generated automatically the first time a query is executed or schemas are listed. By default, the GraphQL schema will be generated from the RDFS/OWL schema in the database but the graphql.auto.schema.source can be changed to use SHACL shapes definitions for GraphQL schema generation.
Each RDFS/OWL class will be mapped to a GraphQL type with one built-in field iri. Any property whose rdfs:domain is set to that class will be added as an additional field to the type. If the property is defined to be owl:FunctionalProperty then it will be a single-valued field, otherwise it will be defined as a multi-valued field. All the classes in the database will be exposed under the top-level QueryType.
As an example, you can load the Star Wars schema to the database and set the configuration option graphql.auto.schema (the database needs to be offline for this option to be set). After that point, all the queries will be validated and answered based on this schema if no schema is specified in the query request.
The auto-generated GraphQL schema is not updated automatically when the source schema is updated. The default schema can be manually removed with the following command so that it will be auto-generated next time it is needed:
$ stardog graphql schema --remove default starwars
The auto-generated schema sometimes might require manual tweaks. If that is the case the auto-generated schema can be exported to a local file and manually updated:
$ stardog graphql schema --show default starwars > starwars.graphqls.
After the local schema file has been updated it can be registered as usual:
$ stardog graphql schema --add default starwars starwars.graphqls
Introspection
Stardog supports GraphQL introspection which means GraphQL tooling works out of the box with Stardog. Introspection allows schema queries to be discovered, exposed, and executed and to retrieve information about the types and fields defined in a schema. This feature is used in GraphQL tools to support features like autocompletion, query validation, etc.
Stardog supports introspection queries for the GraphQL Schemas registered in the system. There is a separate dedicated endpoint for each schema registered in the system in the form http://HOST:PORT/{db}/graphql/{schema}. The introspection queries executed against this endpoint will be answered using the corresponding schema.
Introspection queries are supported by the default GraphQL endpoint only when the auto-generated schemas are enabled by setting the graphql.auto.schema database option to true. Otherwise, there is no dedicated schema associated with the default endpoint and introspection will be disabled.
Implementation
Stardog translates GraphQL queries to SPARQL and SPARQL results to JSON. The CLI command graphql explain can be used to see the generated SPARQL query and the low-level query plan created for the SPARQL query which is useful for debugging correctness and performance issues.
$ stardog graphql explain starwars "{
Human(id: 1000) {
name
knows: friends {
name
}
}
}"
SPARQL:
SELECT *
FROM <tag:stardog:api:context:all>
{
?0 rdf:type :Human .
?0 :id "1000"^^xsd:integer .
?0 :name ?1 .
?0 :friends ?2 .
?2 :name ?3 .
}
FIELDS:
0 -> {1=name, 2=knows}
2 -> {3=name}
PLAN:
prefix : <http://api.stardog.com/>
From all
Projection(?0, ?1, ?2, ?3) [#3]
`─ MergeJoin(?2) [#3]
+─ Sort(?2) [#3]
│ `─ NaryJoin(?0) [#3]
│ +─ Scan[POSC](?0, :id, "1000"^^<http://www.w3.org/2001/XMLSchema#integer>) [#1]
│ +─ Scan[POSC](?0, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>, :Human) [#5]
│ +─ Scan[PSOC](?0, :name, ?1) [#10]
│ `─ Scan[PSOC](?0, :friends, ?2) [#20]
`─ Scan[PSOC](?2, :name, ?3) [#10]
The variables in the SPARQL query will be mapped to objects and field values in the JSON results. The binding for variable 0 will be the root object. The FIELDS output show that 0 is linked to 1 via the name field and linked to 2 via the knows field (note that knows is an alias and in the actual query we have the pattern ?0 :friends ?2).
The GraphQL query plans can also be retrieved by setting the special query variable @explain to true when executing a query.