Getting Started Part 5: Learn Path Queries in Studio
Solve the classic Kevin Bacon problem using Path Queries in Stardog Studio
Page Contents
Introduction
Before you dive in, make sure you’ve worked through Getting Started: Part 4.
Now that you’ve been introduced to some basic concepts, let’s work towards applying them to an actual problem. We’ll work towards a solution to the well known “Six Degrees of Kevin Bacon” problem: given an actor, find movies they appeared in with other actors to get to Kevin Bacon.
There are plenty of websites out there that solve this, so we’re not doing anything revolutionary. But through it we will highlight how Stardog can help you do it in a world with messy data, with previously unknown data sources, and with the flexibility to ask different twists on the underlying question (e.g., ensuring the connections are through bonafide movie stars, not just background actors).
Modeling your data and creating a schema
OK, let’s get going!
Before we actually load any data, we need to create the schema. As with any data modeling exercise, there is no single correct answer. Throughout this guide, we will guide you to one that we think makes sense and explain the thought process behind it.
First, we know that we want to solve the problem of “Six Degrees of Kevin Bacon”, which we can state as:
Given a dataset that includes movies and all the actors that acted in them, take in two different actors and identify the connection between them through movies they were both in.
Let’s restrict this to the simplest case for now: connections are only based on co-acting (i.e., not directing or anything else on a movie) and the only medium is movies (i.e., not TV or other productions). We will expand to those in the next section.
Whiteboarding the schema
With that in mind, let’s build our schema. First: what are the Classes we need to represent? We’ll sketch out the schema in words before we put it into language.
- Actor → The actor
- Movie → What they acted in
While it may seem obvious that each of these Classes should have a name or title, we do have to state that explicitly. This is similar to needing to have an id column and a human-readable name column in a relational database.
Let’s add Datatype Properties to the Classes.
- Actor → The person who is getting connected
- Name → Their name, e.g. “Tom Hanks”
- Movie → What they acted in
- Title → Movie title, e.g. “Toy Story 2”
- Year → Release year, e.g. 1999
And what are the relevant Relationships between those Classes that we need to understand?
- actedIn → In our simple model, the only connection between two Classes is that an Actor Class actedIn a Movie Class.
Writing out the schema
That’s all there is to a very basic data model. In a relational model, you might create tables that look like this:
- Movies: movieID, movieTitle, releaseYear
- Actor: actorID, name
- Roles: actorID, movieID
But for our Knowledge Graph, we do something a little different. We create the data model via triples.
Modeling an Actor
Here is how we model an actor:
:Actor rdf:type rdfs:Class .
:hasName rdf:type rdf:Property ;
rdf:range xsd:string .
Let’s break this down line by line. The first line is saying “the concept of an actor is a first-class concept.” For those familiar with relational databases, it’s like saying there is an actor table that has a uniqueID. Either way, we’re establishing :Actor as something special.
We do that by saying :Actor is a special thing. The rdf:type Relationship is a special Relationship used to say “is a”. (This relationship is so common that you can use a as shorthand and write the triple as :actor a rdfs:Class). We use rdf:type as a convention that is shared across the RDF world. Similarly, rdfs:Class is a conventional way to say “special thing.”
The second line is similar to the first, except it’s saying that :hasName is a Property (aka a Relationship), not a Class.
The third line says that the value of :hasName must be a string. Note that there is a semicolon separating lines two and three. Ending a line with semicolon is syntax to say “the next line has the same subject as this one” so that you don’t need to repeat it. If you want to write everything out, you could write it like this:
:Actor rdf:type rdf:Class .
:hasName rdf:type rdf:Property .
:hasName rdf:range xsd:string .
Modeling a Movie
Adapt the above :Actor model to model a movie that has a string property called “title” and an integer property called “year”. For properties that take on datatypes that are integers, use xsd:integer as the range.
Expand to see the answer
:Movie rdf:type rdfs:Class .
:hasTitle rdf:type rdf:Property ;
rdfs:range xsd:string .
:hasYear rdf:type rdf:Property ;
rdfs:range xsd:integer .
Modeling the Acting relationship
Modeling a Relationship has similar steps to modeling a Class. Instead of rdfs:class, you declare a Relationship by saying it belongs to the class rdf:Property. Note that these Relationships and the Datatype Properties from above (:hasTitle, :hasYear) are both Properties. We use concepts like :range and naming convention (e.g. starting with :has) to help distinguish the properties that act more like relationships and those that act more like descriptors.
Along with declaring it a rdf:Property, you can give :actedIn a domain and range, the domain being the subject of the relationship and the range being the object of the relationship. So :actedIn has a domain of Actor and a range of Movie, which we write as follows
:actedIn a rdf:Property ;
rdfs:domain :Actor ;
rdfs:range :Movie .
Now that we have the schema, we are ready to create a database for this project. To make sure you’re using the exact same schema as we use in the exercise, use a new tab to download the schema.
Create your database to store the movie data by opening Stardog Studio, clicking on “Databases”, and then clicking “Create database” at the bottom. Call it “GettingStarted_Movies” (you can ignore all other options for now).
Add your schema via the “Load data” option. In the databases section, choose the GettingStarted_Movies database and choose “Load data” in the “Other Actions” section. Choose this file.
Confirming your data loading
It should say 11 triples on the database sidebar, but as an excuse to write some SPARQL, go to an editor and write the query to count the triples. You should get 11 there too. See if you can write the query on your own, but it’s included here as well. Make sure you’ve selected the GettingStarted_Movies database on the top bar.
Expand to see the answer
SELECT (count(?s) as ?count)
WHERE {
?s ?p ?o .
}
Hooray, you have a schema! Head back to the “Databases” section and click on the “Schema” tab to visualize your schema - in general, this visual is a helpful way confirm your schema looks as expected and also to onboard others to any project you’re working on.
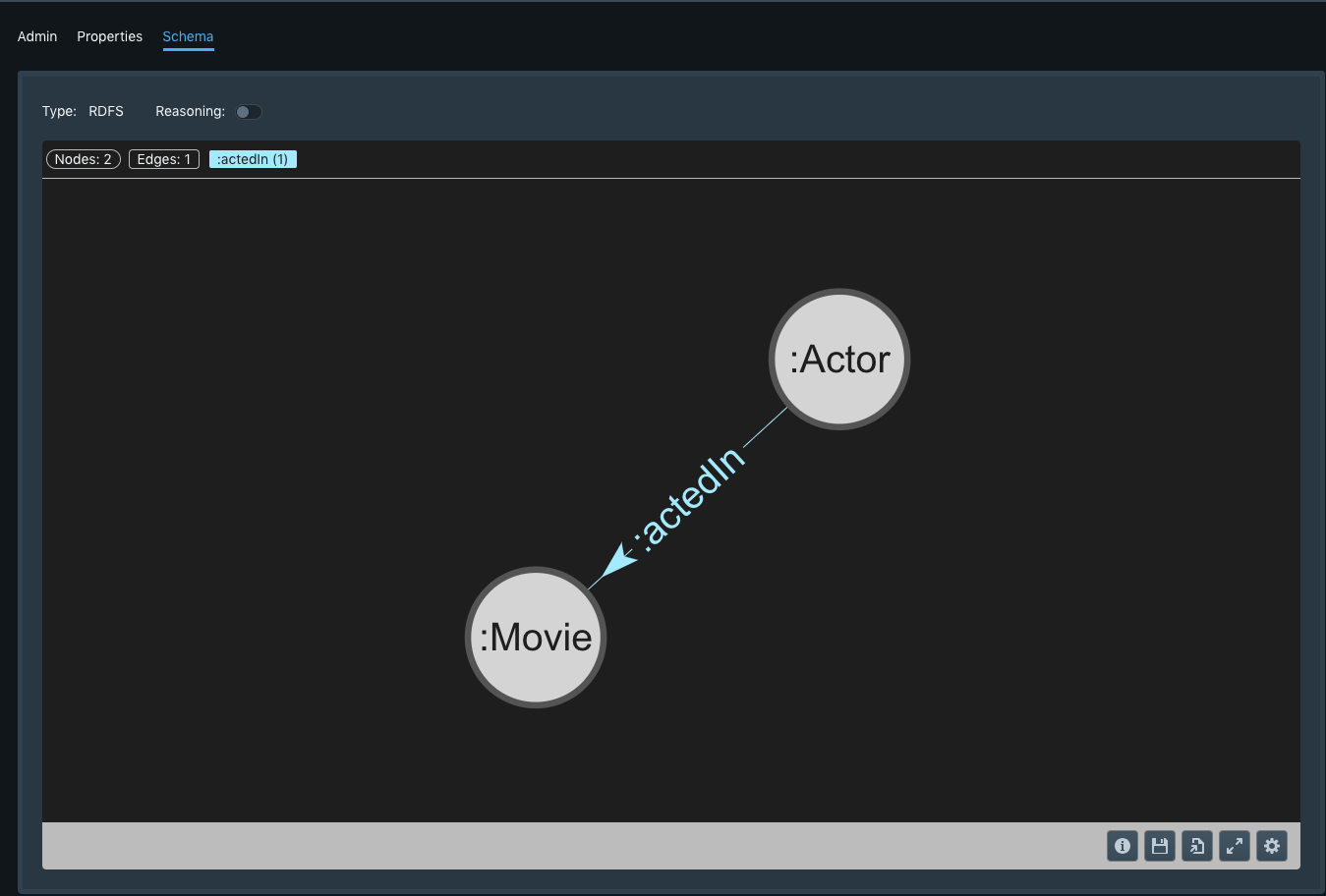
Loading Data
Now that you have the schema, time to load the actual data. We’ve conveniently prepared some actor and movie data that conforms to the schema we created above. In the real world you’d need to do some ETL and data mapping to get here, but for now we’ve taken care of that for you.
Download this data file and load it the same way you loaded the schema above. It will take about a minute to load. In the sidebar it should say 4M triples for this database. Let’s quickly explore this data, using both queries and visualization.
Finding Kevin Bacon
Let’s start with the star of the show - Kevin Bacon! Go back to the “Workspace” section, make sure your language is SPARQL, select the GettingStarted_Movies database, and run this query to make sure he’s in there:
SELECT *
WHERE {
?s :hasName "Kevin Bacon" .
}
Uh-oh, there are two Kevin Bacons! For now, take our word for it that the “real” Kevin Bacon is :nm0000102 . This is his unique identifier based on the IMBD standard.
Describing Kevin Bacon
This is a good opportunity to use the DESCRIBE query, which says “tell me everything you know about this person.” The syntax at it’s most basic is super simple:
DESCRIBE :nm0000102
You’ll get some text results back, but instead change to the visualization tab. Click on the blue circle in the middle - the bottom bar will show you a summary of all we know about Kevin Bacon - that he’s an actor and his name is Kevin Bacon. The visual shows you all of the movies he has acted in.
Well, almost. It shows you the IDs of the movies he’s acted in. In RDF these unique IDs are called IRIs - they are globally unique so that :tt0280380 always refers to the same specific movie, as opposed to a primary key value that is unique only to the specific table or context.
Choose any of the movies, click on it, and choose “expand from node”. This effectively does the same DESCRIBE from above on this node. So now you’ll see the name of a movie and also some actor IRIs. To find someone who is one degree away from Kevin Bacon, choose one of the :nm nodes and expand to get their name (and all the movies they have acted in).
Further exploration
Let’s do a little more exploration of the data to get our feet wet. Use your previous examples from Part 4 as help to ask the following of the data set.
The answers in these and subsequent sections will use the semicolon syntax for two consecutive triple patterns using the same subject. For example, the following pairs of triple patterns are identical.
#Fully written out
?movie :hasTitle ?title .
?movie :hasYear ?year .
#Shorthand with a semicolon
?movie :hasTitle ?title ;
:hasYear ?year .
In the second pair, the semicolon at the end of the first line says, “for the next triple pattern, use ?movie as the subject.” While this only saves us a few keystrokes here, it’s helpful when a query includes a lot of information about a particular subject.
What was Chris Pratt’s first movie?
See hint
The syntax for sort is ORDER BY ASC(?variable) and goes at the very end of your query.
See answer
SELECT ?movie ?title ?year
WHERE {
?chris :hasName "Chris Pratt" .
?chris :actedIn ?movie .
?movie :hasTitle ?title ;
:hasYear ?year .
}
ORDER BY ASC(?year)
Who has acted in the most movies?
See hint
Recall from part 1 the syntax to count songs: SELECT ?s (COUNT(?o) as ?songCount). Use something similar here to count movies (and remember to change the variable name).
See answer
SELECT ?actor ?name (count(?movie) as ?numMovies)
WHERE {
?actor :hasName ?name .
?actor :actedIn ?movie .
}
GROUP BY ?actor ?name
ORDER BY DESC(?numMovies)
Which movies have Tom Hanks and Meg Ryan appeared in together?
See hint
Make sure you use the same variable for both Tom and Meg to act in.
See answer
SELECT ?movie ?title
WHERE {
?meg :hasName "Meg Ryan";
:actedIn ?movie.
?tom :hasName "Tom Hanks" ;
:actedIn ?movie.
?movie :hasTitle ?title .
}
Path Queries: How to get to Six Degrees
As we saw above, there are actually two “Kevin Bacon”s in the data. The other Kevin Bacon does not have a large acting history, so we more or less ignore him for these queries (sorry, other Kevin Bacon). An exercise at the end shows how to ensure you are always using the “real” Kevin Bacon.
A basic answer
To answer the underlying Kevin Bacon problem, we need to use PATHS queries. PATHS is a type of query, just like SELECT, CONSTRUCT, or DESCRIBE.
PATHS is a Stardog-specific query type, an extension of SPARQL Property Paths to better support pathfinding use cases like this one.
As you would expect, PATHS queries find the path(s) from one IRI to another. PATHS queries can help find specific types of paths as well, e.g. the shortest path or a path connected by a certain kind of relationship. Here’s a basic PATHS query:
PATHS
START ?x {?x :hasName "Kevin Bacon"}
END ?y {?y :hasName "Nick Offerman"}
VIA {
?movie a :Movie .
?x :actedIn ?movie .
?y :actedIn ?movie .
} LIMIT 1
The first line says “I want to get from X to Y, but make sure that X has the name Kevin Bacon to start and Y has the name Nick Offerman to end”. Each “hop” of the path will go from an x to a y. At the next stop y from the previous stop becomes x’ and goes to y’, then y’ becomes x” and so on. We know that we start at Kevin Bacon, but this ensures we stop when the y of the hop is Nick Offerman.
The VIA clause says how we want to get there. This one says we want to get there by finding a movie that both x and y have acted in.
We add LIMIT 1 to get one path back, since by default a PATHS query returns any of the shortest paths and there’s likely to be more than one.
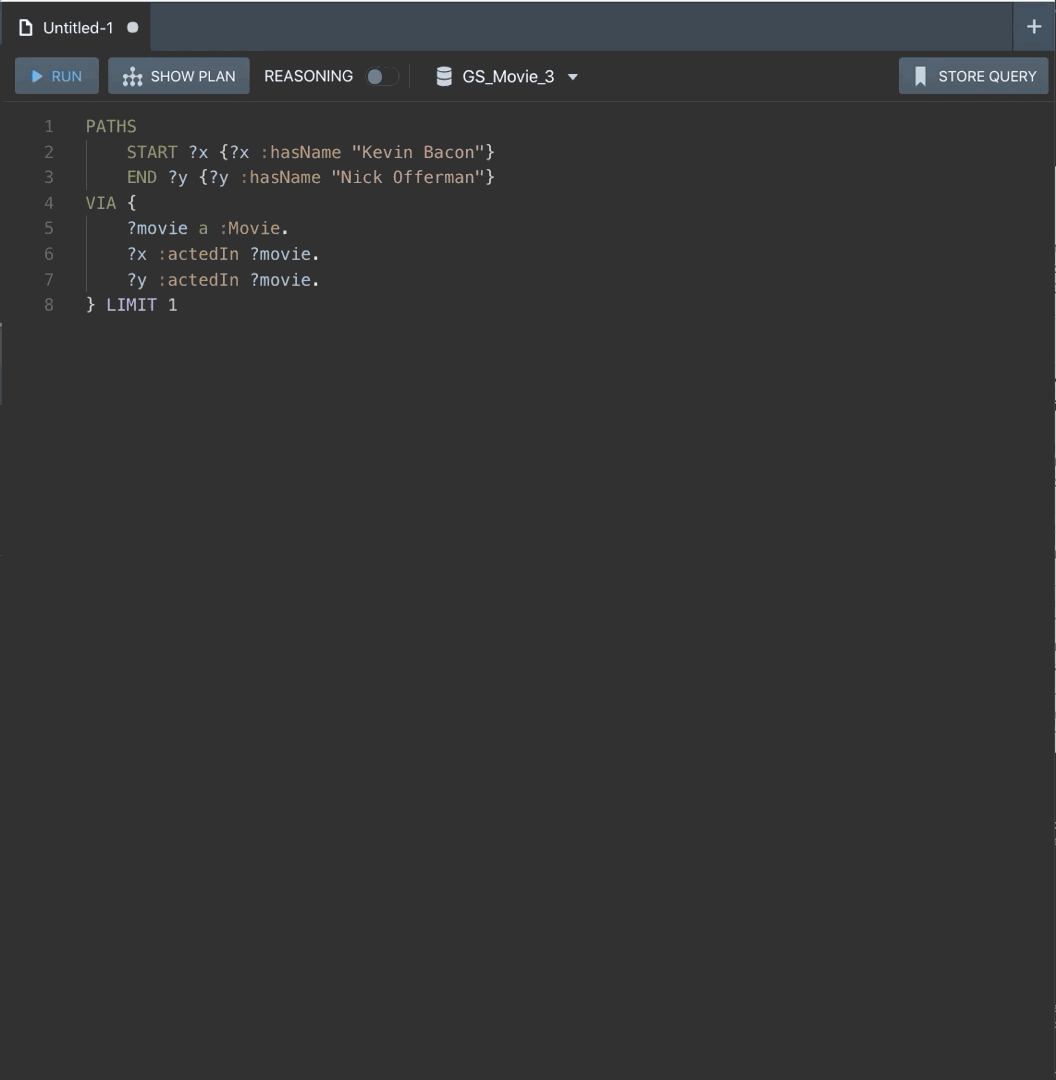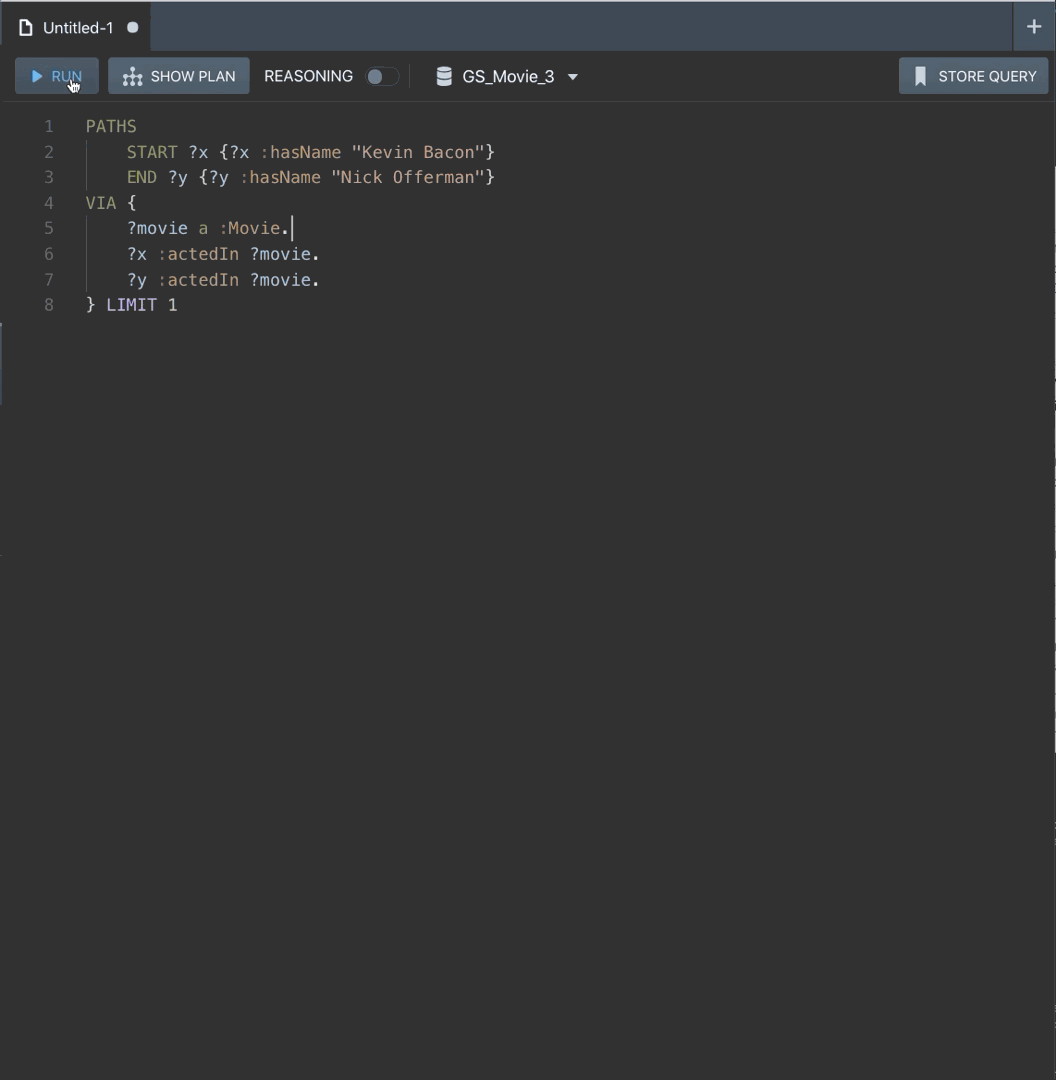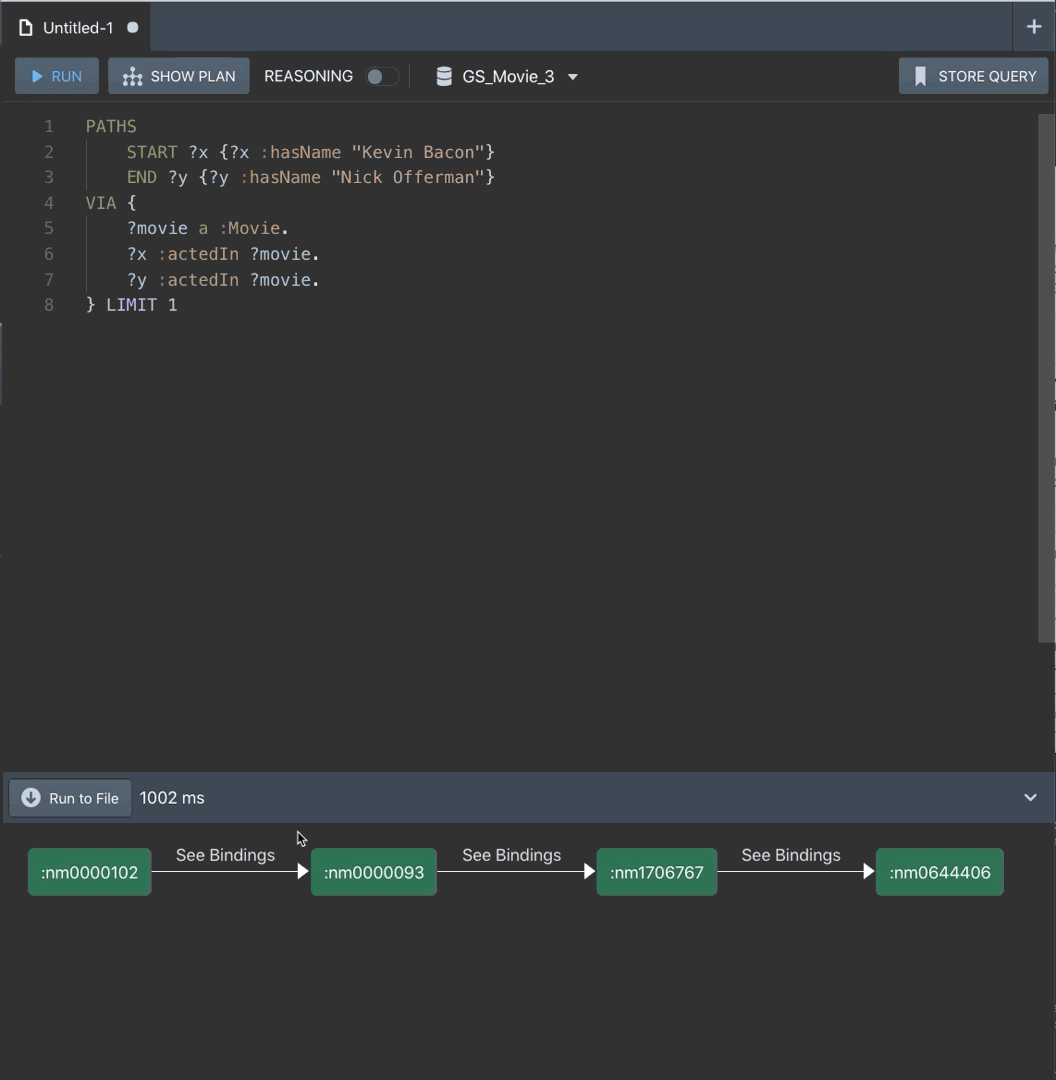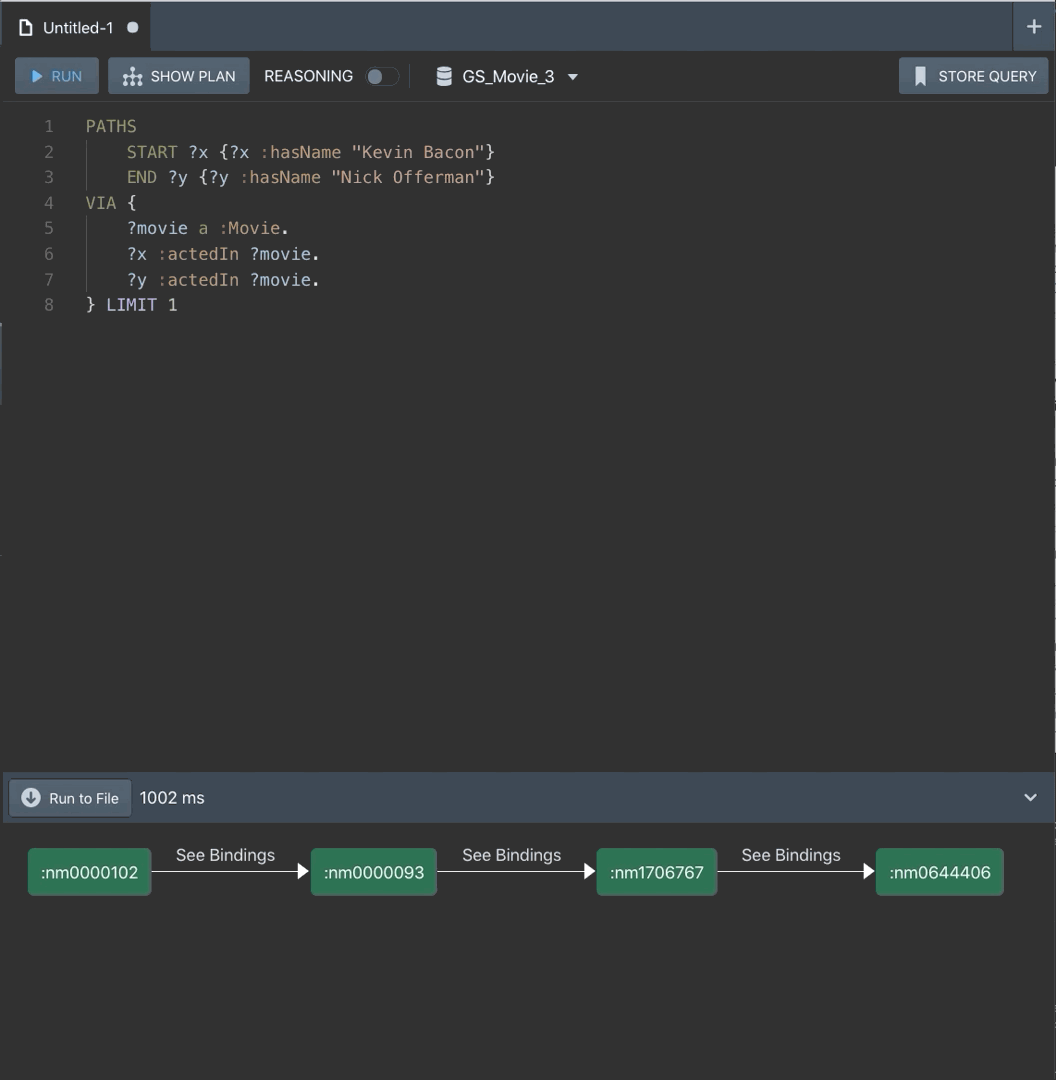
If you run this, you’ll see something that looks like a path, and we can tell that Nick Offerman is three degrees away from Kevin Bacon. If you click on “See Bindings”, you can see the movie that connects them (note your movies may not be the same as the example here). But all of these IRIs are not readable, and we don’t have actor names or titles because we did not explicitly ask for them. So let’s explicitly ask for them:
Adding context
PATHS
START ?x {?x :hasName "Kevin Bacon"}
END ?y {?y :hasName "Nick Offerman"}
VIA {
?movie a :Movie ;
:hasTitle ?title .
?x :actedIn ?movie ;
:hasName ?xName .
?y :actedIn ?movie ;
:hasName ?yName .
} LIMIT 1
The output looks the same, but now we can click on “See Bindings” to see how the connections are made. The easiest way to see the full picture is to click “Run to file” and export to .csv or your preferred file format. Then all the data is in front of you to tell the story in typical “Six Degrees of Kevin Bacon” fashion.
And just like that, we have solved the problem. And look how concise that query is! This is one of the benefits of a Knowledge Graph - since finding connections like this is part of the core use-case, the syntax has language designed to make it easy to write and understand. Think how challenging it would be to write this query in SQL based off of the personMovies table we might have used in a relational model.
Extensions of the problem
You can add to the previous query to add layers to the question. For example, this is how to do it but with only movies released in 2010 or later:
PATHS
START ?x {?x :hasName "Kevin Bacon"}
END ?y {?y :hasName "Nick Offerman"}
VIA {
?movie a :Movie ;
:hasTitle ?title ;
:hasYear ?year .
?x :actedIn ?movie ;
:hasName ?xName .
?y :actedIn ?movie ;
:hasName ?yName .
FILTER (?year >= 2010)
} LIMIT 1
Try inserting your favorite actors (and it doesn’t just have to be Kevin Bacon, though who doesn’t like Tremors?), and then try some other variants.
Six Degrees of Kevin Bacon but you cannot connect via A Few Good Men
See hint
Here is the syntax for not equals: FILTER (?variable != "value").
See answer
PATHS
START ?x {?x :hasName "Kevin Bacon"}
END ?y {?y :hasName "Nick Offerman"}
VIA {
?movie a :Movie ;
:hasTitle ?title .
?x :actedIn ?movie ;
:hasName ?xName .
?y :actedIn ?movie ;
:hasName ?yName .
FILTER (?title != "A Few Good Men")
} LIMIT 1
Ensure the you’re using the “real” Kevin Bacon
See hint
Where in the query are you identifying Kevin Bacon? As the place to start. Instead of looking for Kevin Bacon, try asserting the value that you want to start with.
See answer
PATHS
START ?x= :nm0000102
END ?y {?y :hasName "Nick Offerman"}
VIA {
?movie a :Movie ;
:hasTitle ?title .
?x :actedIn ?movie ;
:hasName ?xName .
?y :actedIn ?movie ;
:hasName ?yName .
} LIMIT 1
Update the query to start and end at a movies instead of Actors
Instead of going from Kevin Bacon to Nick Offerman, go from Toy Story to Casablanca.
See hint
- Make sure the Start and End conditions refer to a title, not a name.
- Instead of connecting on a movie, the connection is now on an actor. So think about flipping movies and actors from the first example.
See answer
PATHS
START ?x {?x :hasTitle "Toy Story"}
END ?y {?y :hasTitle "Casablanca"}
VIA {
?actor a :Actor ;
:hasName ?actorName .
?actor :actedIn ?x .
?x :hasTitle ?xTitle .
?actor :actedIn ?y .
?y :hasTitle ?yTitle .
} LIMIT 1
What’s Next?
Stay in touch with the Stardog team and other Stardog users. Join the Stardog Community forum to share your thoughts.