Mapping Denormalized Data
Learn how to map denormalized data into Stardog.
Distributed databases give us the ability to scale storage far beyond a single, logical machine. Distribution of data via partitioning allows multiple machines to work together to store arbitrarily large data sets. As data is distributed, the cost of traditional joins becomes higher, making the normalized data model problematic. A denormalized model that co-locates joined data can be an attractive alternative. While this obviates the need to perform traditional joins, it creates interesting challenges for virtualization. Let’s examine the challenges and explore solutions.
Denormalized Data
To illustrate, consider a partitioned database instance that is being mapped into the knowledge graph. We’ll assume a design with 5 servers where movies with titles beginning with A-L are on server 0, titles beginning with M-Z on server 1, actors on server 2, roles for actors with even IDs on server 3, and odd IDs on server 4.
For this example, the normalized tables look like this. Note the extra column that indicates the server # is informative and isn’t queried like a normal column.
movie table
| (server) | movie_id | title |
|---|---|---|
| 0 | 0 | Forrest Gump |
| 0 | 1 | Cast Away |
| 1 | 2 | Unbreakable |
actor table
| (server) | actor_id | name |
|---|---|---|
| 2 | 0 | Tom Hanks |
| 2 | 1 | Robin Wright |
role table
| (server) | movie_id | actor_id |
|---|---|---|
| 3 | 0 | 0 |
| 4 | 0 | 1 |
| 3 | 1 | 0 |
| 4 | 2 | 1 |
A query that returns the names of actors that played a role in Forrest Gump looks like this:
SELECT actor.name
FROM movie
INNER JOIN role ON movie.movie_id = role.movie_id
INNER JOIN actor ON role.actor_id = actor.actor_id
WHERE title = "Forrest Gump";
| name |
|---|
| “Tom Hanks” |
| “Robin Wright” |
This query requires information from 4 of the 5 database servers (0, 2, 3, 4). Contrast this with a denormalized design using 1 table that includes movies, roles and actors. We’ll use 5 servers again, this time allocated by movie title. Titles A-B on server 0, C-E on server 1, F-J on server 2, K-M on server 3, and N-Z on server 4.
denormalized
| (server) | movie_id | title | actor_id | name |
|---|---|---|---|---|
| 2 | 0 | Forrest Gump | 0 | Tom Hanks |
| 2 | 0 | Forrest Gump | 1 | Robin Wright |
| 1 | 1 | Cast Away | 0 | Tom Hanks |
| 4 | 2 | Unbreakable | 1 | Robin Wright Penn |
When data is denormalized like this, it becomes possible for the same actor to have a different name for each role, as was the case for Robin Wright Penn in Unbreakable. This could be intentional in cases where we wish to represent the actor’s name at the time they had the role, or it could be a data consistency error that resulted from an update problem.
The SQL query for the names of actors in Forrest Gump becomes:
SELECT name
FROM denormalized
WHERE title = "Forrest Gump";
| name |
|---|
| “Tom Hanks” |
| “Robin Wright” |
All the data needed to answer this query comes from server 2.
Virtualization
Let’s look at how to map these tables to a virtual graph. The goal will be to create a graph like this:
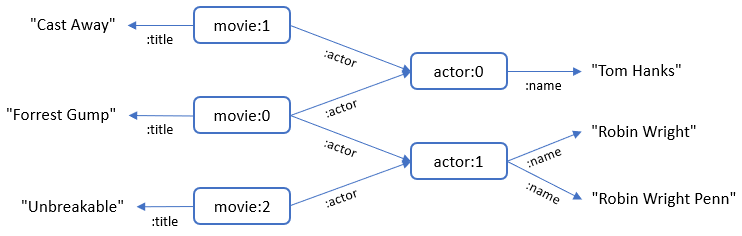
The mappings, in SMS2 syntax, for these tables are:
Normalized Mappings
PREFIX : <http://example.com/>
MAPPING <urn:movies>
FROM SQL {
SELECT `movie_id`, `title`
FROM `movie`
}
TO {
?movie :title ?title .
} WHERE {
BIND(template("http://example.com/Movie-{movie_id}") AS ?movie)
}
;
MAPPING <urn:roles>
FROM SQL {
SELECT `movie_id`, `actor_id`
FROM `role`
}
TO {
?movie :actor ?actor .
} WHERE {
BIND(template("http://example.com/Movie-{movie_id}") AS ?movie)
BIND(template("http://example.com/Actor-{actor_id}") AS ?actor)
}
;
MAPPING <urn:actors>
FROM SQL {
SELECT `actor_id`, `name`
FROM `actor`
}
TO {
?actor :name ?name .
} WHERE {
BIND(template("http://example.com/Actor-{actor_id}") AS ?actor)
}
Denormalized Mappings
PREFIX : <http://example.com/>
MAPPING <urn:movie_actor_roles>
FROM SQL {
SELECT `movie_id`, `title`, `actor_id`, `name`
FROM `denormalized`
}
TO {
?movie :title ?title ;
:actor ?actor .
?actor :name ?name .
} WHERE {
BIND(template("http://example.com/Movie-{movie_id}") AS ?movie)
BIND(template("http://example.com/Actor-{actor_id}") AS ?actor)
}
The SPARQL for our Forrest Gump actors query is:
Normalized
select ?name {
graph <virtual://normalized> {
?movie :title "Forrest Gump" ;
:actor ?actor .
?actor :name ?name .
}
}
| name |
|---|
| “Tom Hanks” |
| “Robin Wright” |
Denormalized
select distinct ?name {
graph <virtual://denormalized> {
?movie :title "Forrest Gump" ;
:actor ?actor .
?actor :name ?name .
}
}
| name |
|---|
| “Tom Hanks” |
| “Robin Wright” |
| “Robin Wright Penn” |
You might not expect the last record from the denormalized query given there is no row in the source table with both “Forrest Gump” and “Robin Wright Penn” when the query seems to explicitly constrain the results to those actors from “Forrest Gump”. Why does this happen?
Let’s break down the query. It consists of three triple patterns. Each triple pattern matches a set of solutions:
Triple Pattern #1
?movie :title "Forrest Gump"
| movie |
|---|
| :Movie-0 |
Triple Pattern #2
?movie :actor ?actor
| movie | actor |
|---|---|
| :Movie-0 | Actor-0 |
| :Movie-0 | Actor-1 |
| :Movie-1 | Actor-0 |
| :Movie-2 | Actor-1 |
Triple Pattern #3
?actor :name ?name
| actor | name |
|---|---|
| :Actor-0 | “Tom Hanks” |
| :Actor-1 | “Robin Wright” |
| :Actor-1 | “Robin Wright Penn” |
Each of these solution sets are joined together. The order of the joining doesn’t matter. Let’s start by joining the first and second solution sets by their common binding, which is ?movie. The result is:
| movie | actor |
|---|---|
| :Movie-0 | Actor-0 |
| :Movie-0 | Actor-1 |
The third and fourth solutions from the second triple pattern {(movie=:Movie-1, actor=Actor-0), (movie=:Movie-2, actor=Actor-1)} are dropped because there are no solutions from the first pattern that include movies :Movie-1 or :Movie-2. The third set of solutions is joined with the first two by their common binding, actor. The final result is:
| movie | actor | name |
|---|---|---|
| :Movie-0 | :Actor-0 | “Tom Hanks” |
| :Movie-0 | :Actor-1 | “Robin Wright” |
| :Movie-0 | :Actor-1 | “Robin Wright Penn” |
As a side note, this last last examples illustrates what logically happens. In practice, database engines employ an optimizer that finds more efficient ways to build these solutions.
Scoping Queries to the Data of Interest
To avoid returning every name associated with an actor when working with denormalized data, let’s change our query from asking “What are the names of the actors that acted in Forrest Gump?” to asking “What were the names of the actors when they acted in Forrest Gump?”. To express this in SPARQL, we need a new node that represents acting in a movie. This node is analogous to the role table in the normalized model, so we’ll create a :Role node for that. The new graph becomes:
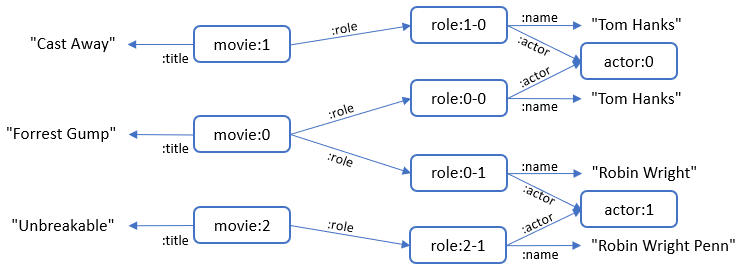
By hanging the actor name off the role node, we permit actors to have different names, yet we can formulate queries that scope the name to a specific role. Also note that we retain the Actor node, albeit without properties, so we can write Kevin Bacon-style queries that link movies by their common actors.
The SMS2 for this scoped mapping looks like this:
Scoped
PREFIX : <http://example.com/>
MAPPING <urn:movie_scoped_actor_name>
FROM SQL {
SELECT `movie_id`, `title`, `actor_id`, `name`
FROM `denormalized`
}
TO {
?movie :title ?title ;
:role ?role .
?role :actor ?actor ;
:name ?name .
} WHERE {
BIND(template("http://example.com/Movie-{movie_id}") AS ?movie)
BIND(template("http://example.com/Role-{movie_id}-{actor_id}") AS ?role)
BIND(template("http://example.com/Actor-{actor_id}") AS ?actor)
}
The SPARQL for our Forrest Gump actors query becomes:
select distinct ?name {
graph <virtual://scoped> {
?movie :title "Forrest Gump" ;
:role ?role .
?role :name ?name .
}
}
| name |
|---|
| “Tom Hanks” |
| “Robin Wright” |
If, for some reason, you wanted to know all the names of the actors from Forrest Gump, you can still achieve the results from the denormalized mappings by changing the query:
select distinct ?name {
graph <virtual://scoped> {
?movie :title "Forrest Gump" ;
:role ?role .
?role :actor ?actor .
?allRoles :actor ?actor ;
:name ?name .
}
}
| name |
|---|
| “Tom Hanks” |
| “Robin Wright” |
| “Robin Wright Penn” |
Conclusion
In this tutorial we showed how the choice of mappings can affect query performance. Generally the main consideration in data modeling is how you wish to query your data. This example illustrates how a design decision in the source system (to denormalize data) can influence the choice of data model in the Knowledge Graph as well.