Stardog Voicebox Developer Guide
This chapter provides information to developers about how to make sure Stardog Voicebox will work effectively and accurately.
Page Contents
Stardog Voicebox is available to use with your own data for Essentials and Enterprise customers.
Overview
This developer’s guide provides information about how to make sure Stardog Voicebox will work effectively and accurately.
Getting Started
In order to use Voicebox with your own data, follow these steps:
- Create your data model and connect to your data sources in Designer.
- Publish your data model into a new database with Voicebox enabled.
- Generate example questions in Explorer, Studio or the CLI.
That’s it! Once you follow these steps, you can go to the Voicebox tab in Stardog Cloud and start having a conversation.
When you are publishing your data model to a new database, make sure the Voicebox checkbox is selected as shown here:
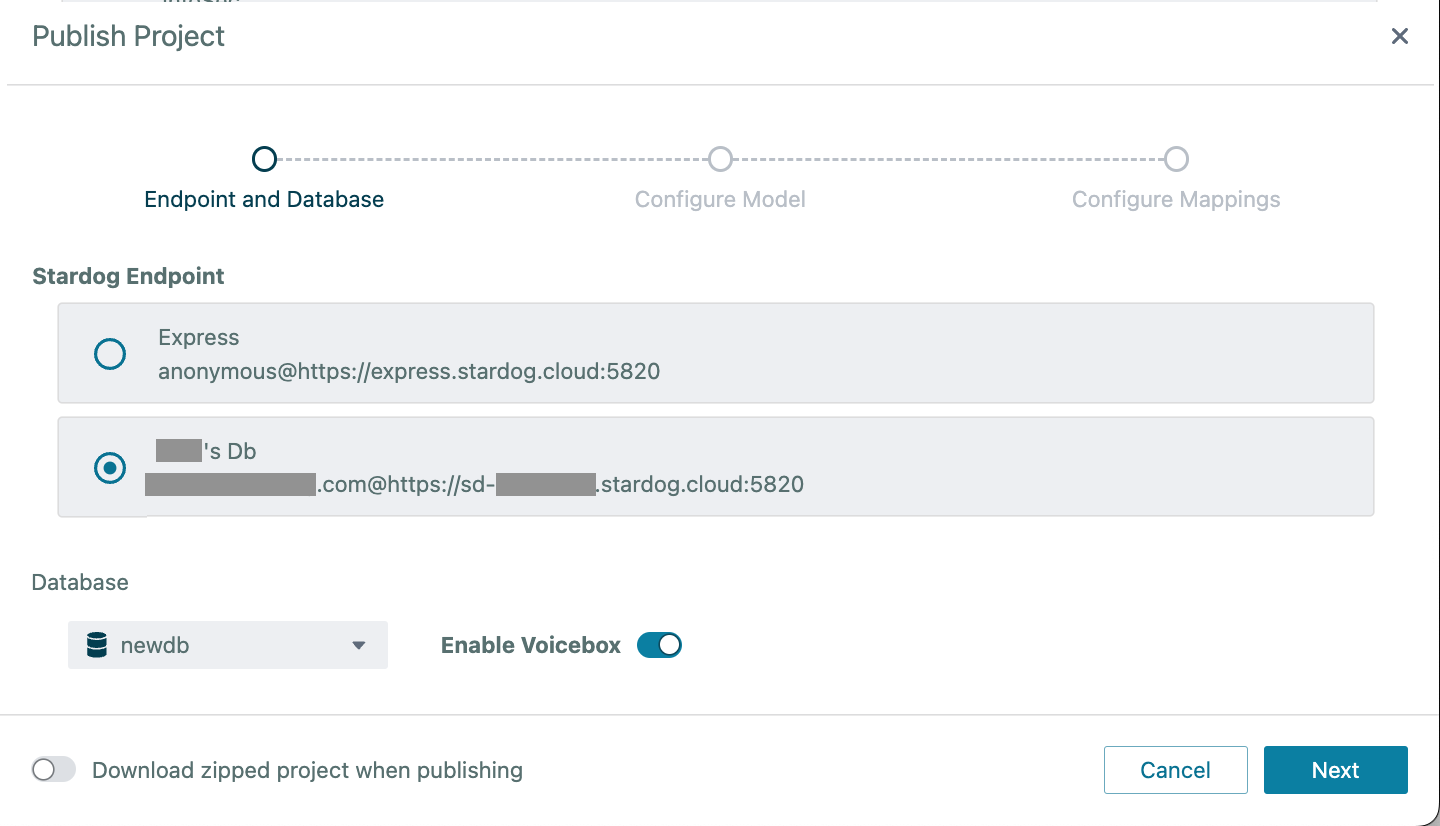
The Voicebox option will only be available if 1) your Stardog installation has a license that allows Voicebox, and 2) you have not exceeded the number of Voicebox databases allowed in your license.
If you would like to use Voicebox with an existing database, you have to set the database option voicebox.enabled manually. See the Database Configuration section for more details on this topic.
It is strongly suggested to create manual example queries. See the Stored Queries for more details about adding example queries, and make sure you follow the guidelines outlined below when creating these examples.
Data Modeling
Voicebox is developed to work with data models created by Designer but you can bring your own data models created elsewhere as long as they conform to the guidelines outlined in this section. The key information used by Voicebox in data models to generate SPARQL queries are:
- Labels and descriptions of classes and properties. For schema elements only
rdfs:labelandrdfs:commentare used for labels and comments respectively. Thelabel.propertiesdoes not have an effect on schema. - Class hierarchy as defined by
rdfs:subClassOf. - Property domain and range information as defined by
so:domainIncludesorso:rangeIncludes. - Prefixes must be unique. Two IRIs that are referenced from more than one prefix (esp. The default
_:prefix) may confuse the LLM.
Data models should be clear and as concise as possible for Voicebox to make sense of the model and successfully generate SPARQL queries. General data modeling best practices apply for Voicebox too:
- Make data models as concise as possible. Avoid importing entire large ontologies when you’re only going to be using a fraction; import only what your need – or better yet, create a minimal model in Designer and align it to other models later.
- Use clear and understandable labels for classes and properties. Avoid abbreviations or ambiguous terms in labels.
- Avoid using literals (attributes) in your data model as much as possible and instead use IRIs (relationships) in your data model. For example, the
stateproperty in anAddressclass should be an IRI and not a literal. IRIs allow Voicebox to link query results to graph elements, which is not possible with literals (see Stored Queries section for more discussion on this topic). - If you are using attributes, make sure you use the most appropriate type. For example, use
xsd:dateorxsd:integerwhere appropriate instead ofxsd:string. - Voicebox recognizes
rdfs:domainandrdfs:range, but you should avoid using these constructs in data models as much as possible. Assigning multiple domains and ranges with the RDFS vocabulary has unintended consequences for reasoning, so useso:domainIncludesorso:rangeIncludesinstead.
Needless to say, the data model should reflect how the instance data is represented. Ideally, there are SHACL constraints associated with the data model so that the instance data can be validated with respect to these constraints. Minimally the domains and ranges of attributes and relationships should be validated.
Although only one schema can be active at a time, multiple schemas may coexist within a Voicebox database. Voicebox will reference only the schema selected in the settings when answering questions.
Stored Queries
To achieve the best accuracy on question answering for your knowledge graph, we recommend adding stored example queries that demonstrate key usage or important parts of your schema. They are also your opportunity to demonstrate quirks in the data, e.g. perhaps for legacy reasons a field is typed as a string but is actually numeric. You can add a stored query to demonstrate using int or strdt to create an appropriate typed value to use for comparisons.
You can also codify answers of specific queries that drive demos, or key behaviors in applications built on Voicebox, by storing relevant, related queries.
We recommend a few stored examples to start, no more than 5 to 10; in aggregate, your stored examples queries should demonstrate usage of the entire data model. Variety is much more important than volume.
Add new queries as needed over time to address user feedback and new use cases. Stored queries can be created in Studio, Explorer, or the CLI. You typically will not need more than 50 to achieve high accuracy (>90%) for your use case.
Adding queries
For a stored query to be used by Voicebox, it should satisfy the following three conditions:
- The query is public; in other words, not marked as private.
- The query is associated with a specific database.
- The query has a metadata field,
system:voiceboxQuestion, wheresystemis the namespace (http://system.stardog.com/), that assigns one or more natural language questions with the query. The metadata field is automatically added by Explorer and Studio as explained below.
The database should have the option voicebox.enabled=true set before the queries are stored. If this option is enabled after stored queries are already added, those queries should be readded. See the next section that discusses details for indexing.
Studio and Explorer provide UI components to add the natural language questions: 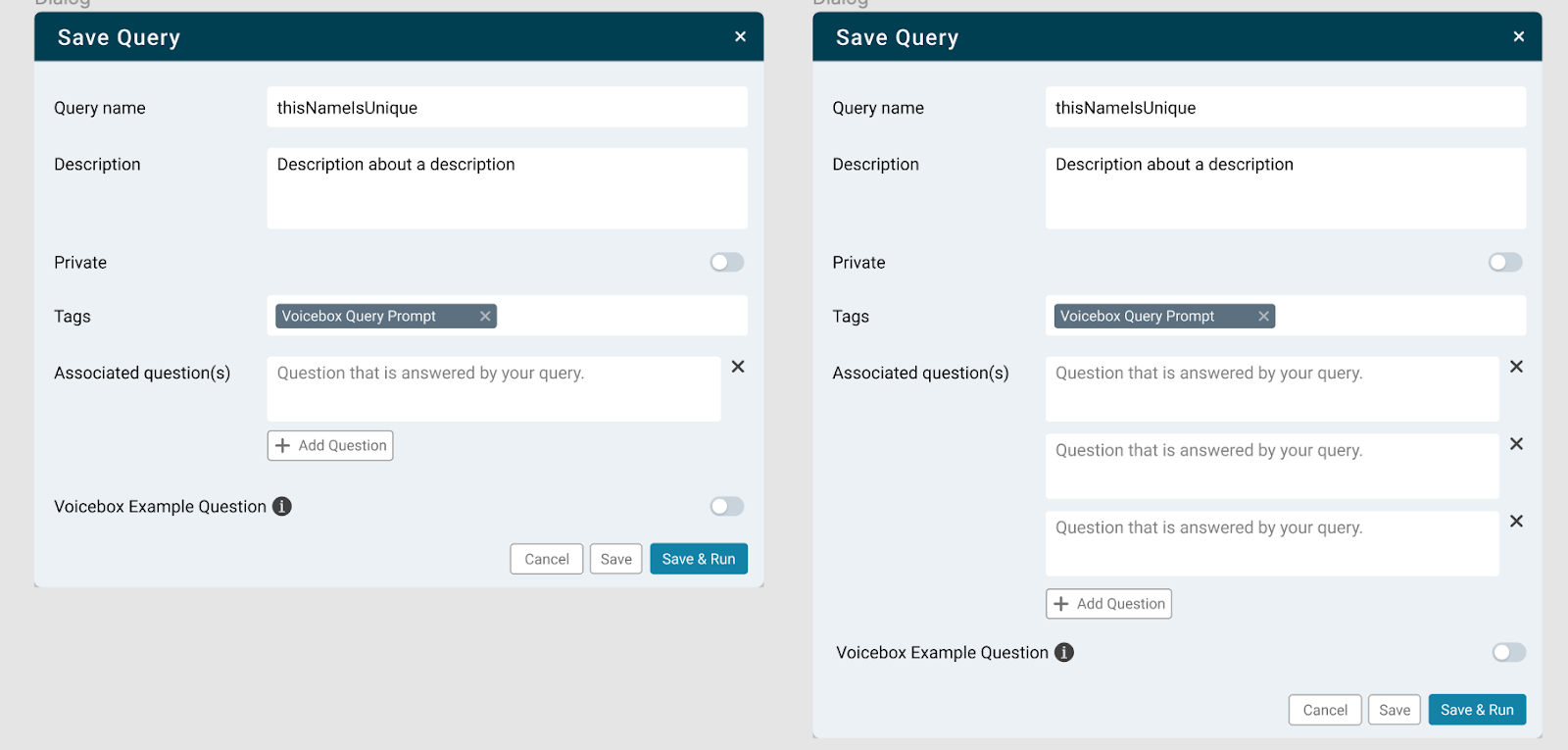
The Voicebox metadata field can also be set via the command-line as well:
stardog-admin stored import ListProductBrands.ttl
where ListProductBrands.ttl would look like (with DBNAME and USERNAME set to appropriate values):
@prefix stardog: <tag:stardog:api:> .
@prefix system: <http://system.stardog.com/> .
system:QueryQ10000 a system:StoredQuery , system:SharedQuery ;
system:queryName "ListProductBrands" ;
system:queryDatabase "DBNAME" ;
system:queryCreator "USERNAME" ;
system:voiceboxQuestion "List all Product Brands", "Find all the product brands" ;
system:queryString """SELECT DISTINCT ?productBrand0
WHERE {
?productBrand0 a scm:Product_Brand .
}""".
Query preprocessing
When a query matching the constraints listed in the previous section is stored in Stardog, the information about this stored query is automatically added to the named graph system:VoiceboxQuestions after several preprocessing steps.
This named graph is updated in a background thread, so if multiple stored queries are being added with stardog-admin stored import, it might take a few seconds or minutes for all the queries to appear in this named graph. Use stardog-admin ps list to check the background process.
The stored query information in this named graph will look like this:
system:QueryMyQuery a system:StoredQuery , system:SharedQuery ;
system:queryName "MyQuery" ;
system:voiceboxQuestion "First natural language question" ,
"Second natural language question" ;
system:queryString """ ... SPARQL Query ... """ .
Whenever a stored query is updated, the information in this named graph will be updated automatically as well. Do not update this named graph directly, because the changes might be lost! Always update the stored query, and changes will be reflected in this named graph.
The SPARQL query string will look different from the stored query string. This is due to preprocessing steps applied automatically before the query info is copied to this named graph. These preprocessing steps make all stored queries have canonical formatting, and they automatically apply some of the guidelines described in the next section.
The preprocessing steps make changes to queries that may cause them to return a different set of results than the original version. These changes are meant to make queries more generic and reusable while fixing typical user mistakes. If queries are written by advanced users following the guidelines below, it is better to disable preprocessing by setting the database configuration option voicebox.preprocessors=noop, as explained below.
In Stardog 10, the following preprocessors will be used by default:
- ReplaceConstantIris This preprocessor will detect entity IRIs used in queries, find their labels in the data, and replace IRIs with a variable linked to the label using
stardog:label. Type or property IRIs will not be affected. - ReplaceLabelFilters This preprocessor will detect constants or equality filters used by
rdfs:labeland replace them withstardog:label. - RenameVariables This preprocessor will replace Explorer-generated variables names that look like
?subjN,?subj0, or?obj0with meaningful names based on types and properties used in the query. - LabelPropertyFunction This preprocessor ensures the
stardog:labelandstardog:property:textMatchusage in queries are serialized using property function syntax and not the SERVICE syntax. - OrderJoins This preprocessor reorders the triple patterns in the query so related triple patterns are grouped together.
The preprocessing can be controlled by the database configuration option voicebox.preprocessors. The default value for this option will use all the preprocessors described above. Setting this option to noop will disable all preprocessing steps. This option can also be set to a comma-separated list of preprocessor names to choose specific preprocessors.
Voicebox preprocesses each stored query when it is created or updated, using the namespaces defined for the database at that time. These namespaces are stored as part of the preprocessed query. If a namespace that was referenced by a stored query is later removed or changed in the database, subsequent Voicebox operations may report missing or invalid namespace errors in diagnostic reports. To correct this, you can re-run preprocessing on all published queries using the following command (replace SERVER_URL and DB_NAME with the appropriate values):
stardog-admin --server SERVER_URL db optimize -o optimize.vacuum.data=false optimize.voicebox=true -- DB_NAME
Guidelines for writing queries
Follow these guidelines when creating stored queries:
- Voicebox only supports SELECT queries. Only create SELECT queries.
- Avoid duplicates in results, and use DISTINCT as much as possible.
- Do not use FROM or FROM NAMED statements in your queries.
- Do not specify prefixes in your queries. Those should be specified in the database so Voicebox can understand them.
- Always test your queries by running them to make sure they return the expected answers.
- Voicebox assumes your examples are right. If they’re not, it will potentially result in incorrect queries.
- Always make sure the labels are clear and correct. If you mis-label, Voicebox does not know and will use queries incorrectly.
- Questions can be written as instructions, too.
- Question: “Who is the oldest person?”
- Instruction: “Find the oldest person”.
- Queries should be about instance data. Do not write queries about schema.
- Do not include redundant conditions in your queries that are not necessary to answer the question. For example, if your question is “Which spacecrafts have hyperdrive rating greater than 1?”, the query you build should not include anything about ship capacity, length, manufacturer, etc. Remove any pattern or constraint from the query that does not contribute to the result.
- The queries should always return IRIs and not labels. Voicebox retrieves the labels for IRIs before presenting the results to the user and links those labels with the IRIs. If queries don’t return IRIs, links will be missing in the results.
- Projection variables in the query should match the question. For example, if the query is asking “Find all the orders that …”, the query should have the projection “SELECT DISTINCT ?order”. If you are building the query in Explorer, pay attention to the “Results shown” selection and uncheck any type that is not asked in the question. One exception to this rule is about entities mentioned in the question. See the next bullet point for an example.
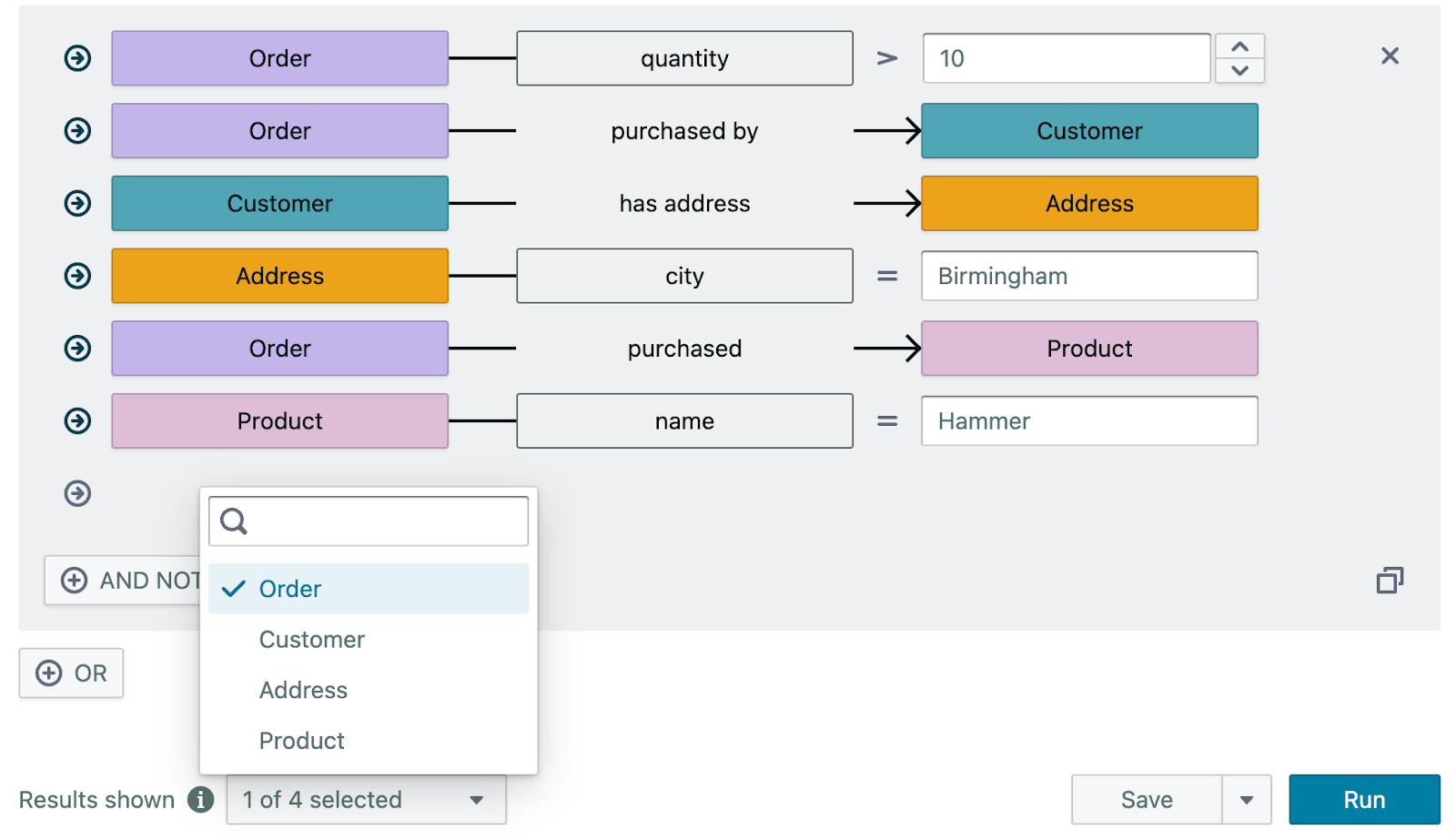
- Do not use constants in your queries for entities. This means do not use the “In” operator in Explorer queries, and do not use IRIs (other than for properties and classes) in Studio queries. Instead, the query should find the entity (typically using the label of the entity). For example, if the question is “Find movies directed by Steven Spielberg.”, the query should look like this in Studio:
SELECT DISTINCT ?movie ?director WHERE { ?movie a so:Movie . ?movie so:director ?director . ?director stardog:label "Steven Spielberg" . }or like this in Explorer:

- Use
stardog:labelin queries instead ofrdfs:label.stardog:labelis a new service added in Stardog 10 that finds entities matching a label (or vice versa). It takes advantage of full-text search, so it can do fuzzy matching. It can also look up multiple label properties if thelabel.propertiesoption is configured to do so. - If the question is asking about a count, the query should be an aggregation query returning the count. For example, if the question is asking “How many products were sold in selling point X?”, the query should not return the products, but just the count. For aggregation queries that use GROUP BY, the grouping variables may be returned. For example, the query “How many products were sold each year?” would have a
GROUP BY ?yearexpression, and the variable?yearshould be returned. Conversely, if the query is not asking about a count explicitly, the query should return the entities and not a count. - There should not be any extraneous ORDER BY, GROUP BY, or LIMIT in the queries if they are not required by the question. For example, if the question is asking “What are the top three …” or “Show me five …”, the LIMIT in the query is justified. Otherwise, there should not be a LIMIT, even if the query returns a very large number of results.
- Use meaningful variable names in your queries instead of generic names like
?x,?y, or unnamed variables like bnodes []. When queries are generated by Explorer, the auto-generated variable names like?subj0and?obj0are used, but Voicebox automatically renames those variables based on types and properties used in the query.
DOs and DON’Ts
The following table summarizes the above advice:
| DOs | DON’Ts |
|---|---|
| Create SELECT queries | Create UPDATE queries |
| Use DISTINCT as much as possible | Have duplicates in your results |
| Run your queries to make sure they return the expected answers | – |
| Write some of your questions as instructions | – |
| Write questions about instance data | Write questions about schema |
| – | Include conditions in your query that aren’t required to answer the question |
| Return IRIs | Return labels |
| Select the variables mentioned in your question | Select variables not mentioned in your question |
| Find the entity your query is looking for | Use constants for entities |
Use stardog:label | Use rdfs:label |
| Aggregate queries that ask for a count | Include other variables when you ask for the count |
| – | Use ORDER BY, GROUP BY, or LIMIT if they are not required by the question |
| Use meaningful variable names | Use variable names like ?x or bnodes |
| Define prefixes in the DB | Define prefixes in the query |
| – | Use FROM/FROM NAMED in queries |
Database Configuration
The database configuration option voicebox.enabled needs to be set to true for Voicebox to work with a database. This option can be set at any time, but it is best practice to set this option at database creation time.
This option can be set to true only if the license for the Stardog server allows Voicebox to be enabled. Stardog licenses have a metadata field voicebox.count.limit that specifies the maximum number of databases that can have Voicebox enabled at any time. You can run stardog-admin license info to see this field for your license.
If a database is created with Stardog 9 or earlier, the default reasoning schema is set to tag:stardog:api:context:local, which is a built-in wildcard. This is not compatible with Voicebox. The default reasoning schema should be set to one or more specific named graphs before Voicebox can be enabled. Use the command stardog reasoning schema -–list DB to see the list of schemas and their associated graphs and the command stardog reasoning schema -–add to update the schema graphs.
If named graph security is enabled for the database, all users should be given read access to the named graph http://system.stardog.com/VoiceboxQuestions. If a user does not have access to this named graph, they will not be able to see the example queries, and Voicebox will not be able to answer their questions accurately. See Query Preprocessing for more details about this named graph.
Setting the option voicebox.enabled will automatically trigger various other database options to be configured as well. No further administrator action is required for the additional options to be set. Information about these additional options are provided below for completeness.
search.enabled=true- This option enables full-text search for the database. It is required for Voicebox to find entities referenced in user questions, among other tasks. This search uses Lucene’s lexical matching capabilities.
search.index.contexts.filter=tag:stardog:api:context:localsearch.index.contexts.excluded=false- The above two options together enable full-text search over all the named graphs in the database.
search.semantic.enabled=truesearch.semantic.index.contexts.filter=http://system.stardog.com/VoiceboxQuestions, [all graphs of the default schema]- This option enables semantic search over specific named graphs in the database. Semantic search is powered by vector search and requires each text literal to be turned into vectors for indexing. For this reason, it is only enabled over the special named graph that contains stored queries (see the Stored Queries section below) plus reasoning schema graphs.
search.semantic.model=””- This option specifies which language model should be used by semantic search to turn text values into vectors. The default is an empty string, which means the default language model included in the Stardog distribution should be used. This default model is all-MiniLM-L6-v2. However, any other language model from HuggingFace can be used as an alternative.
- A valid value looks like this:
search.semantic.model="djl://ai.djl.huggingface.pytorch/sentence-transformers/paraphrase-albert-small-v2". You can see more about supported protocols and address variants here.
- A valid value looks like this:
- This option specifies which language model should be used by semantic search to turn text values into vectors. The default is an empty string, which means the default language model included in the Stardog distribution should be used. This default model is all-MiniLM-L6-v2. However, any other language model from HuggingFace can be used as an alternative.
search.index.properties.excluded=http://system.stardog.com/queryString- This option excludes SPARQL query strings from the vector index. SPARQL queries are typically long strings and costly to vectorize, and they don’t need to be included in the vector search.
search.index.compute.norm=true- This option specifies that text lengths (norms) should be computed and indexed. This means text length will influence scores for full-text search and yield more accurate results.
label.properties=http://www.w3.org/2000/01/rdf-schema#label- This option specifies which properties are used to associate labels with entities. When Voicebox is looking for an entity mentioned in a user question, it will only consider the options specified here to find the matching entities.
reasoning.schema.versioning.enabled=true- This option enables internal change tracking functionality for reasoning schema graph. This allows Voicebox to detect that the schema for the database has been updated without inspecting the contents of the schema graphs.
- Because of schema versioning, Voicebox will automatically reflect changes to the default schema graphs, but it does not support serving from a historical schema snapshot, since that functionality is not covered by schema versioning.
- This option enables internal change tracking functionality for reasoning schema graph. This allows Voicebox to detect that the schema for the database has been updated without inspecting the contents of the schema graphs.
reasoning.precompute.non_empty.predicates=false- This option disables a reasoning optimization that is not compatible with schema versioning. This optimization is most useful when database contents (schema or data) are mostly static, so disabling it does not have a negative impact on typical usage.
Common pitfalls
Below are some common issues users run into when using Stardog Voicebox:
- Creating no or too few example queries.
- Issues with namespaces
- Editing or removing the default namespace for a database.
- Using a prefix in a query that is not defined in the database’s namespace.
- Using a prefix in a query that is mapped to a different IRI in the database’s namespace.
- Using multiple prefixes for the same namespace. e.g., both
schemaandsofor<https://schema.org/>.
- Issues with stored queries
- Training Voicebox on queries that are not stored queries. (Resolution: reload all stored queries)
- Deleting stored queries. (Resolution: reload all stored queries)
- Failing to process stored queries. (Resolution: process new queries after they’re stored)
- Using an example query that’s too long.
- Using classes or properties in training queries that are not in an ontology.
A diagnostics tool is available to check for these issues. On the manage endpoints page, go to the three-dot menu actions for the endpoint being validated and select View Diagnostic Report. Scroll down to the Voicebox Report section, select the database and data model for validation, and click Generate Report. 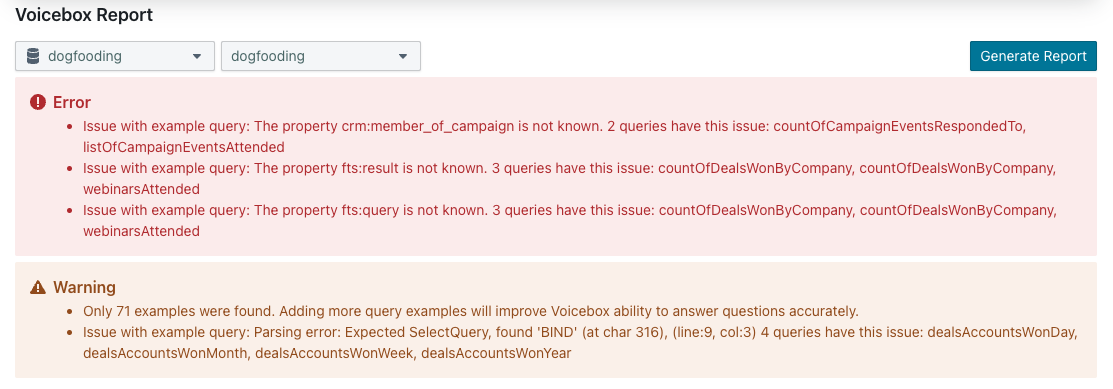
API Access
API access to Voicebox is currently limited and not enabled for most users. Please contact Stardog for availability and access information.
Stardog Voicebox is available via an API as well. If your organization has been given Voicebox API access then you will see an option to “Manage API Keys” in the menu in the lower left corner:
On the API management page first click “New Voicebox App” and choose an endpoint and a database for your app. You will also have the options to customize the connections details such as the data graph and the schema that will be used by your app. Be sure to enable reasoning if you have inference rules in your database.
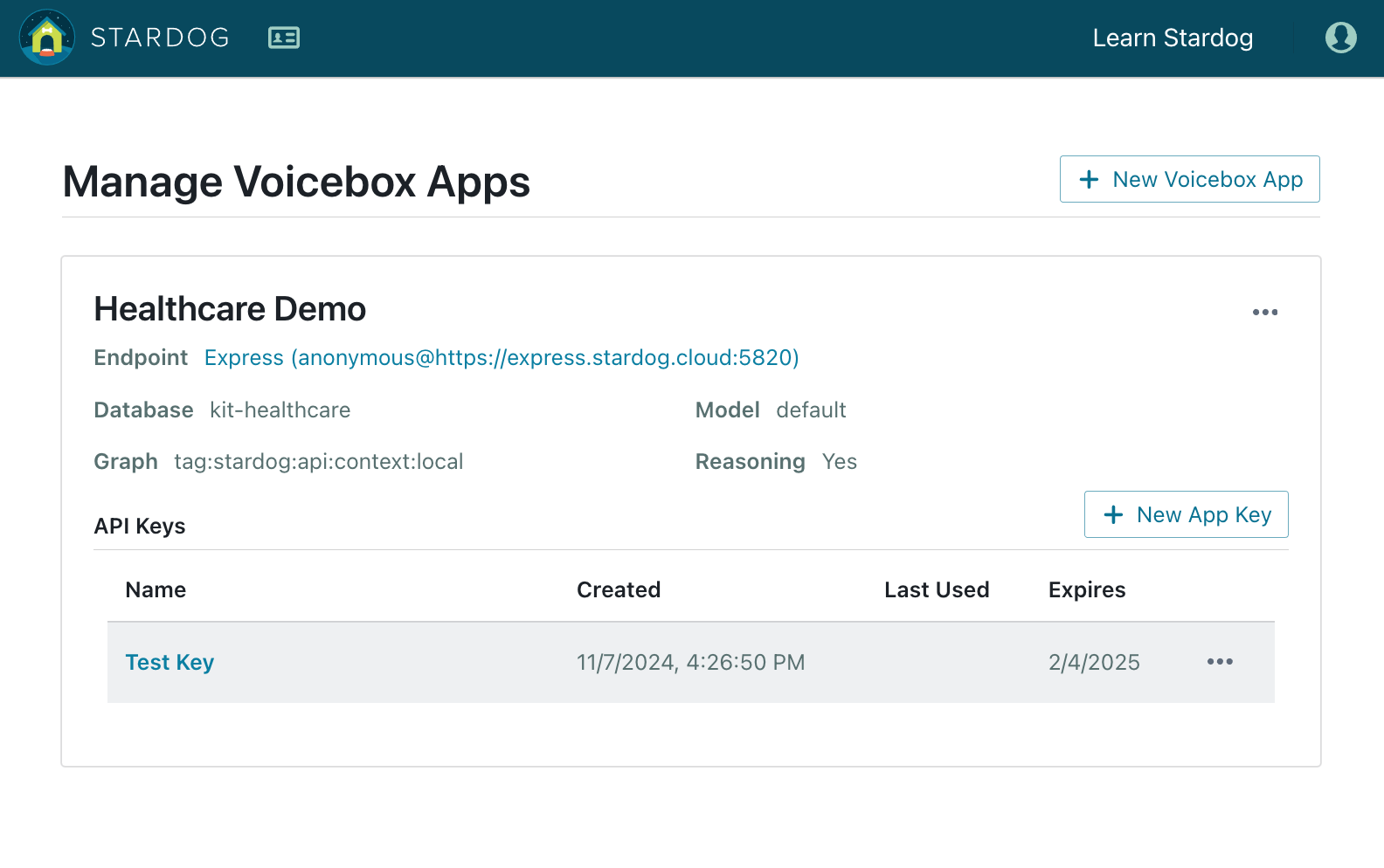
After the app is created, you can click “New App Key” to create your API key. You can choose an expiration date for your key. Once your API key is created make sure you copy the key before closing the window because you will not have access to the key again.
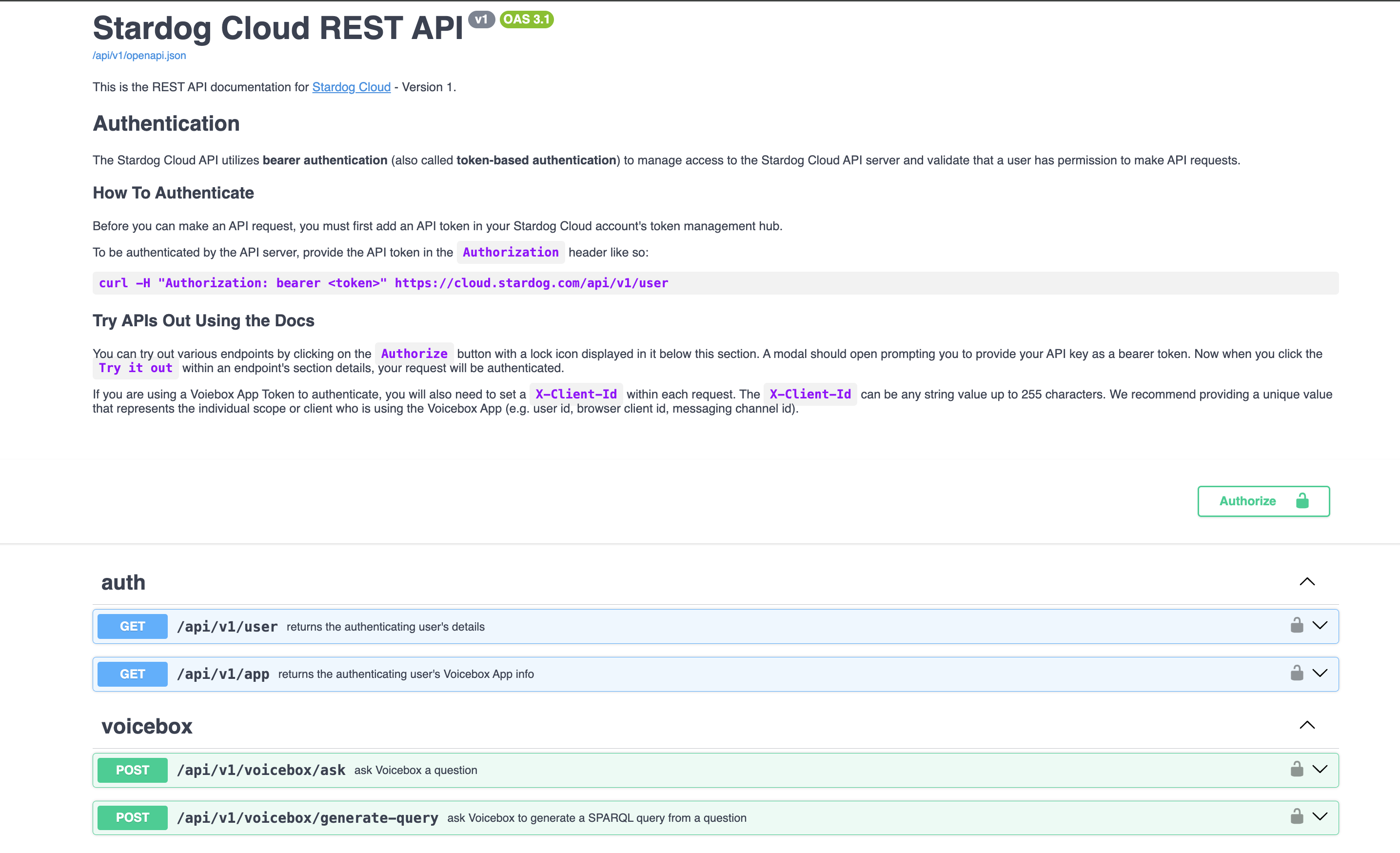
Voicebox API is accessible via HTTP and is documented here. In the document page you can click the “Authorize” to enter your API key to test the endpoints directly within your browser.
Integrations
Voicebox can be integrated with external AI assistants and developer tools through the Model Context Protocol (MCP), an open standard for connecting LLM applications to data sources and tools.
Stardog Cloud MCP Server
The Stardog Cloud MCP Server exposes Voicebox to any MCP-compatible host application, including Claude Desktop, Claude Code, Cursor, and custom MCP clients, so you can ask natural language questions of your Stardog knowledge graphs directly from those environments.