Getting Started Part 1: Introduction to Knowledge Graphs
Learn foundational concepts about the Knowledge Graph
Page Contents
Introduction
This is the first part of the Getting Started series, which puts Knowledge Graph concepts in action and introduces the SPARQL query language. It was designed for technologists of all backgrounds and assumes no knowledge of Stardog, though it does presume some basic familiarity with query languages and relational databases.
Part 1 explains foundational concepts necessary to start interacting with Stardog in Getting Started: Part 2 and onward.
What is a Knowledge Graph?
Knowledge is messy – any given concept can mean different things to different people, carry layers of associations, and be connected to a multitude of other concepts. Given the complexities of knowledge, capturing it in a machine-readable format can be nearly impossible without the right tool. Knowledge graphs are purpose-built to achieve this goal; Stardog is based on the RDF open standard which was created to represent large-scale information systems.
We define knowledge graph as a representation of data that is enriched with real-world context, is based on the graph data structure, and has a flexible schema that allows for multiple definitions of the same data. Read on for definitions of these key concepts, or if you are familiar with knowledge graphs, you can go straight to Getting Started: Part 2.
The graph data structure
To define graph, let’s start by comparing it to a more familiar concept — relational systems, like tables. Relational databases are optimized for efficient storage and retrieval of transactional data. Relational data has fixed data definitions determined by the column headers. Those definitions in the column headers help make up the database’s schema. A schema is the set of rules that govern a database, effectively stating what data can or can’t enter the system.
In contrast, the graph data structure is designed to highlight relationships between concepts. In graph, data is expressed as a triple – two “nodes” connected by an “edge.” For example, the sentence “The Beatles sing the song Yesterday” would be expressed as a triple with two nodes, “The Beatles” and “Yesterday”, connected by an edge with type “sings”. Or we could express the sentence “Yesterday was released in 1965” with nodes “Yesterday” and “1965” connected by a “releaseYear” edge.
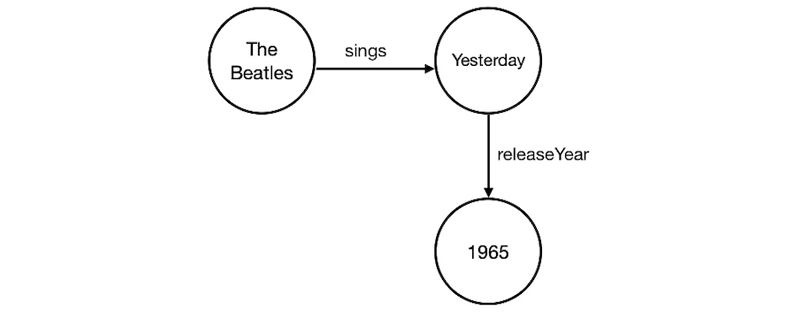
Graph easily accepts new information about nodes, simply creating new edges to relate additional data to the existing data. In comparison, in a relational system, adding a type of data that is not already accounted for in the schema requires creating a new schema and a new combined dataset. The graph schema’s ability to accept new information makes it ideal for projects with agile release cycles or new incoming data streams.
Graph vs. Knowledge Graph
Graph has been popularized through graph databases, which support applications with changing or highly interconnected data. Where knowledge graphs differ is that they also support many layers of associations or conflicting definitions of the same data. Simply put, a graph database is still only designed to support one point of view, whereas the knowledge graph’s schema supports multiple points of view.
As we stated above, a knowledge graph is a representation of data that is enriched with real-world context, is based on the graph data structure, and has a flexible schema that allows for multiple definitions of the same data. As a result, knowledge graphs can easily support projects where multiple departments are collaborating or where requirements are changing.
About Stardog
A knowledge graph is only as powerful as the data it can access, but accessing data in real-world IT environments can be challenging. Stardog’s platform provides tools to address these challenges:
- Virtualization connects data remotely, whether data lives in the cloud or on-prem
- Connectors to SQL and NoSQL databases map data from common data sources
- Voicebox is a conversational AI interface that enables natural language question answering over your enterprise data
- Translates questions into SPARQL queries and returns grounded, hallucination-free answers
- Processes unstructured documents like PDFs and Word documents, making their content queryable alongside structured data
The value in unifying data is the trusted insights interpreted from the data. Stardog offers a suite of tools to help reveal new insights and to ensure that results are actionable:
- Built-in machine learning improves model quality by allowing data scientists to train models against complete, up-to-date data
- Path queries trace data lineage and find distant, indirect links across data sources
- Data Quality Constraints help ensure data is correct by finding, flagging, and/or preventing conflicting data
- The Inference Engine displays all logic for each result, providing details required to operationalize insight
Getting Started Resources
We have a variety of resources to get you started with Stardog.
Blogs
We’ve highlighted some of our foundational blogs below. Additional blog posts are available on our blogs page.
- What is a Knowledge Graph - provides the foundation for the problems Stardog aims to solve.
- Learning SPARQL with Interactive Tutorials - provides an overview of the interactive tutorials embedded in Stardog Studio.
Tutorials
We’ve highlighted some of our foundational tutorials below. Additional tutorials are available on our training portal.
- RDF Graph Data Model - Learn about the RDF graph model used by Stardog.
- Learn SPARQL in Studio - Write Knowledge Graph queries using SPARQL with step-by-step examples.
Video Trainings
We’ve highlighted some of the foundational trainings below. Additional trainings are available on our training portal.
-
Getting Started with RDF & SPARQL
Learn about:
- The basics of the RDF graph model
- How to build a simple SPARQL query, step-by-step
- Stardog’s SPARQL extension to find shortest paths
- More advanced SPARQL features like optional values, negation and aggregation
-
Reasoning with RDF Graphs and Ontologies
Learn about:
- What reasoning means and how it relates to data modeling
- The basics of reasoning with RDFS and OWL ontologies
- How to use user-defined rules for inferring new types and edges in RDF graphs
- Using reasoning with SPARQL queries inside Stardog Studio
- How logical reasoning relates to statistical reasoning and machine learning
-
Learn about:
- The basics of RDF data validation
- The core features of the SHACL language
- How SHACL validation interacts with RDFS/OWL reasoning
- Stardog’s integrity constraint validation capability for validating SHACL constraints
Community
Need some help? Want to be part of the Stardog Community? Our Community page is a great resource to discuss Stardog and Stardog Studio, make support requests, ask questions, etc.
What’s Next?
- Ready to dive in? To continue on with the Getting Started series, head on over to Getting Started: Part 2.
- Want to learn more about our data model first? Read up on the RDF open standard that Stardog is based on here.