Stardog Voicebox
This chapter discusses Stardog Voicebox, our conversational AI chat interface for your Enterprise Data.
Page Contents
Overview
Stardog Voicebox is a conversational AI chat interface designed to enable anyone (any user persona) to ask any question (point, path, descriptive, predictive, geospatial) on any data (structured, semi-structured, un-structured), hallucination-free. It combines the power of Large Language Models (LLMs) and knowledge graphs, as part of an agentic architecture to enable natural language interactions and deliver actionable insights.
With Voicebox, you can ask questions and get answers using domain-specific language, relevant to your use case and knowledge workers. Answers are grounded in enterprise knowledge (i.e. based on facts) and based on the most up-to-date information, leveraging the power of Stardog’s powerful data federation engine, for dynamic querying into your enterprise sources. Voicebox provides traceability and explainability so users have trust in the accuracy and reliability of each response.
The following steps describes the high-level flow of a user interaction with Voicebox:
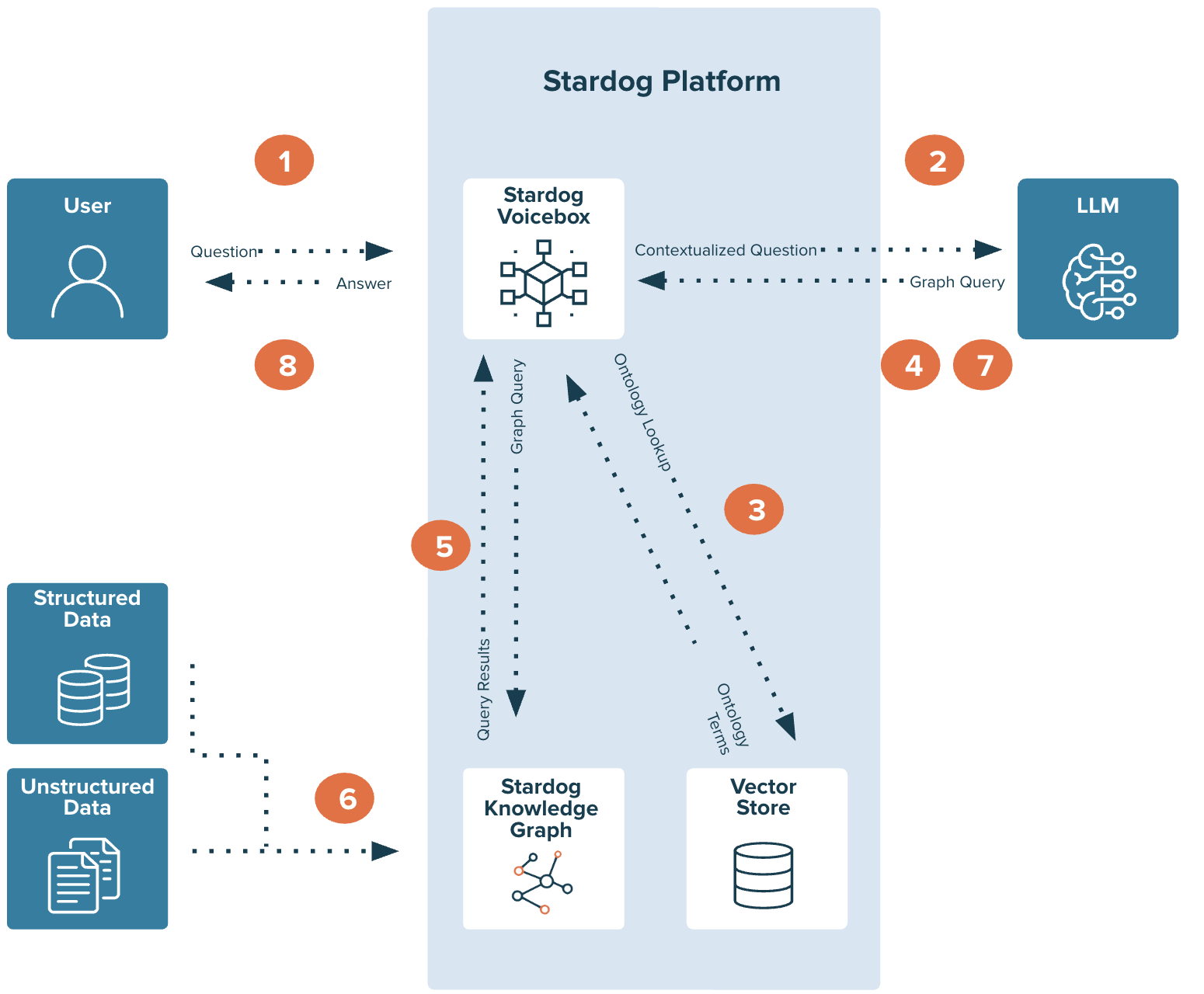
- User asks a question in natural language.
- Voicebox, leveraging the power of the LLM, identifies key semantic concepts from the user text.
- Voicebox uses the embedded vector store to match the semantic concepts from the text to the semantic concepts of the underlying ontology/model along with any user provided relevant few shot examples for additional domain context.
- The model concepts, along with the few shot examples are presented to the LLM to generate a structured SPARQL query.
- The generated SPARQL query is automatically translated to a query plan with multiple SQL queries based on the source mappings.
- The generated query plan is executed to dynamically access enterprise data in a federated manner based on the mappings.
- The results are summarized in plain language using the LLM.
- The results are presented to the user.
What about hallucinations?
LLMs are susceptible to generating factually incorrect outputs, referred to as “hallucinations.” Stardog Voicebox mitigates this by utilizing knowledge graphs as a core component of its question and answering process.
Voicebox translates natural language queries into SPARQL queries, which are then executed against the Stardog Knowledge Graph. This approach ensures that responses are derived from structured, verifiable data within the knowledge graph, grounding LLM outputs to reliable sources of truth.
The knowledge graph functions as a controlled vocabulary and structured representation of domain knowledge, enabling precise data retrieval and minimizing ambiguity. The use of SPARQL ensures that queries are executed against a defined data model, improving the accuracy and reliability of the responses.
Voicebox distinguishes between information generated by RAG/code/external LLMs and data retrieved directly from the knowledge graph. Voicebox tracks the source of information, indicating whether it was derived from RAG, code execution, external LLMs, or direct queries to the knowledge graph. When a query cannot be executed against the data within the Knowledge Graph, Voicebox returns the response, “Cannot find an answer for this question,” indicating that the requested information is not present within the accessible data sources or within the context specified in the given ontology.
Getting Started with Voicebox
No setup needed
To immediately experience the capabilities of Voicebox, you can utilize our pre-configured Voicebox Knowledge Kits. These kits are designed to showcase Voicebox’s functionalities with curated datasets, allowing you to explore and interact with data through natural language queries without any initial setup or configuration. Simply select a Knowledge Kit from the available options to begin your Voicebox experience.
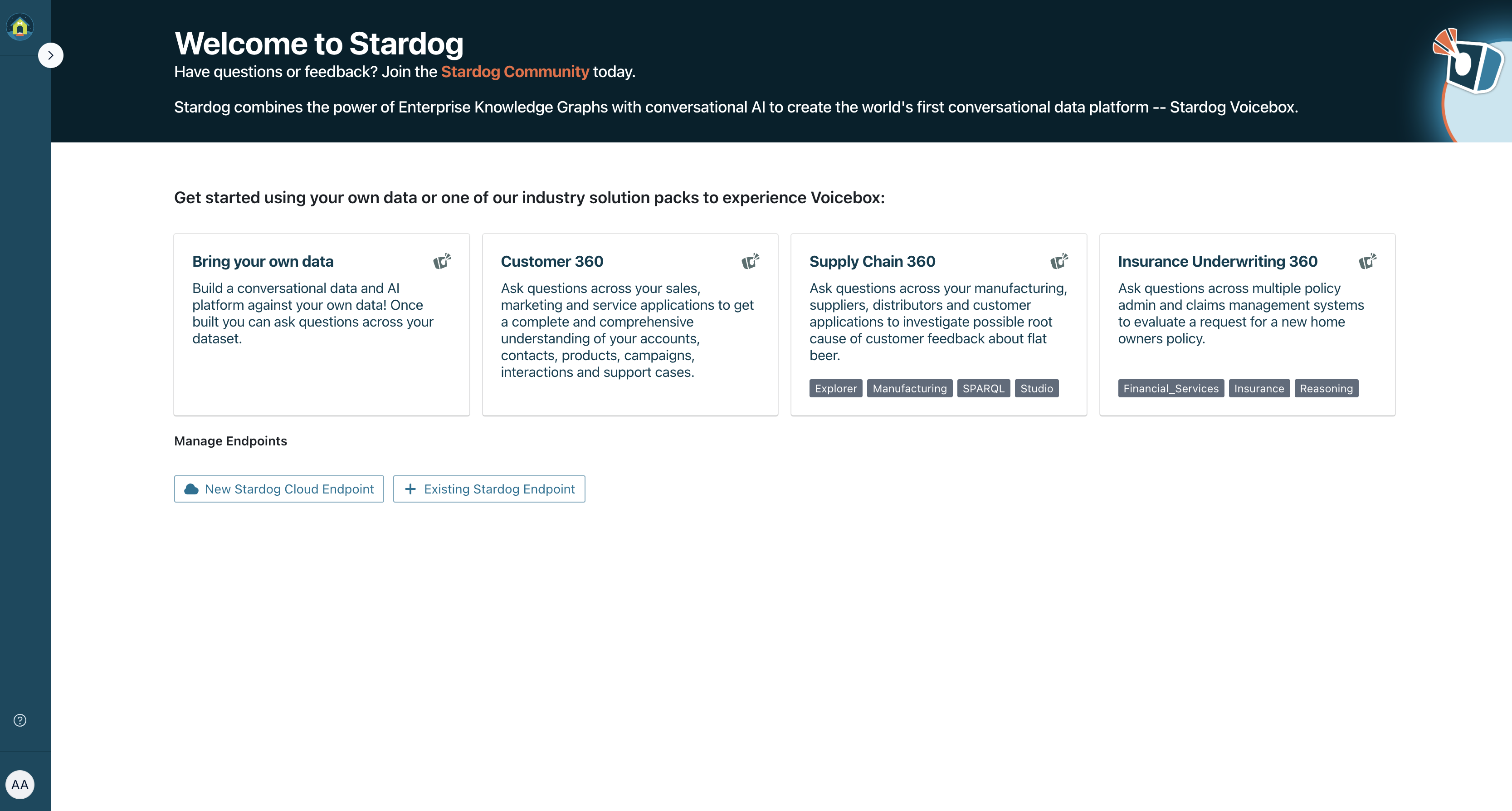
Selecting a Knowledge Kit opens a conversational interface with example questions to guide your initial interactions, providing a straightforward way to start exploring the data and understand Voicebox’s query handling.
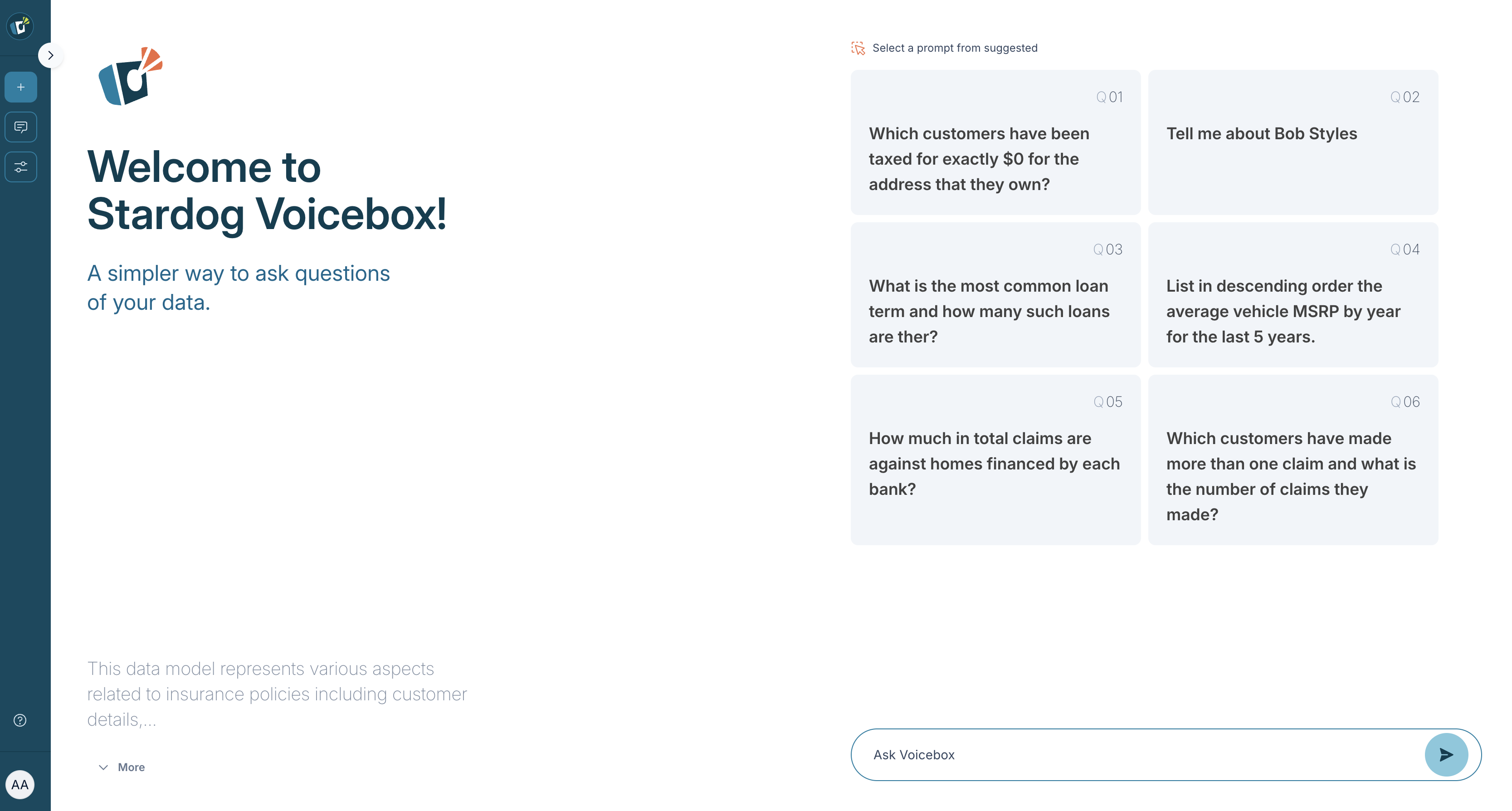
From there, either click on one of our pre-selected queries or type your own. All queries are asked in plain English - no knowledge of SPARQL required!
Using Stardog Voicebox against your own data
Stardog Voicebox is also available to use with your own data for Cloud and On-Prem/Virtual Private Cloud customers.
To utilize Voicebox with your own data, you will need to set up an endpoint and configure your data sources as outlined in the Stardog Voicebox Developer Guide. The guide provides detailed instructions on how to connect your data, define your schema, and configure any necessary rulesets to ensure accurate and relevant responses.
Understanding Voicebox
Home panel
The home panel is your starting point for interacting with Voicebox. It’s the first screen you’ll see and is designed to initiate your data exploration. This panel offers a selection of pre-defined example queries, often referred to as “spotlight questions,” to help you get started. Voicebox also features a text input area where you can directly enter your own natural language questions to begin your conversation.
Chat interface panel
The chat interface panel is your primary area for interacting with Voicebox. It allows you to submit queries and view the system’s responses. There are also a number of different action icons you may use:
- Retry: If necessary, you can retry a query.
- Info Icon: You may hover over to see how Voicebox interpreted your question.
- Copy Response: You can copy Voicebox’s response for use elsewhere.
- Copy Query: You can copy the SPARQL query, allowing you to easily re-run or modify it.
- Download Results: If Voicebox provides data in a structured format, you may download the results for further analysis.
![]()
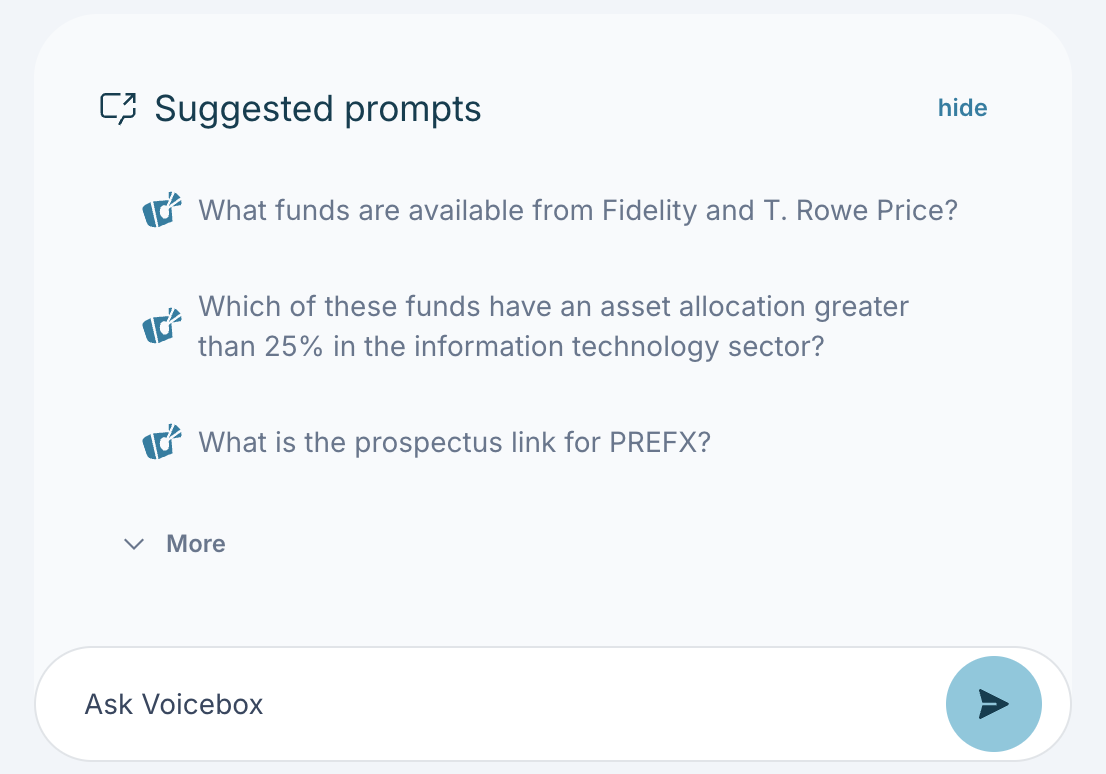
Within the chat interface, you can view a list of suggested prompts to help you formulate your next query or explore related topics.
Chat history panel
The chat history panel provides a record of your previous conversations with Voicebox, allowing you to review past interactions. Conversations are organized by database, with each database (e.g., “all_paws_wealth,” “wealth-rag”) listed as a distinct section. Within each section, you’ll see a list of your conversations, along with the associated count of questions asked. This organization helps you quickly find and revisit your interactions within a specific data context. The panel also includes a search bar at the top, enabling you to search your history for specific keywords.
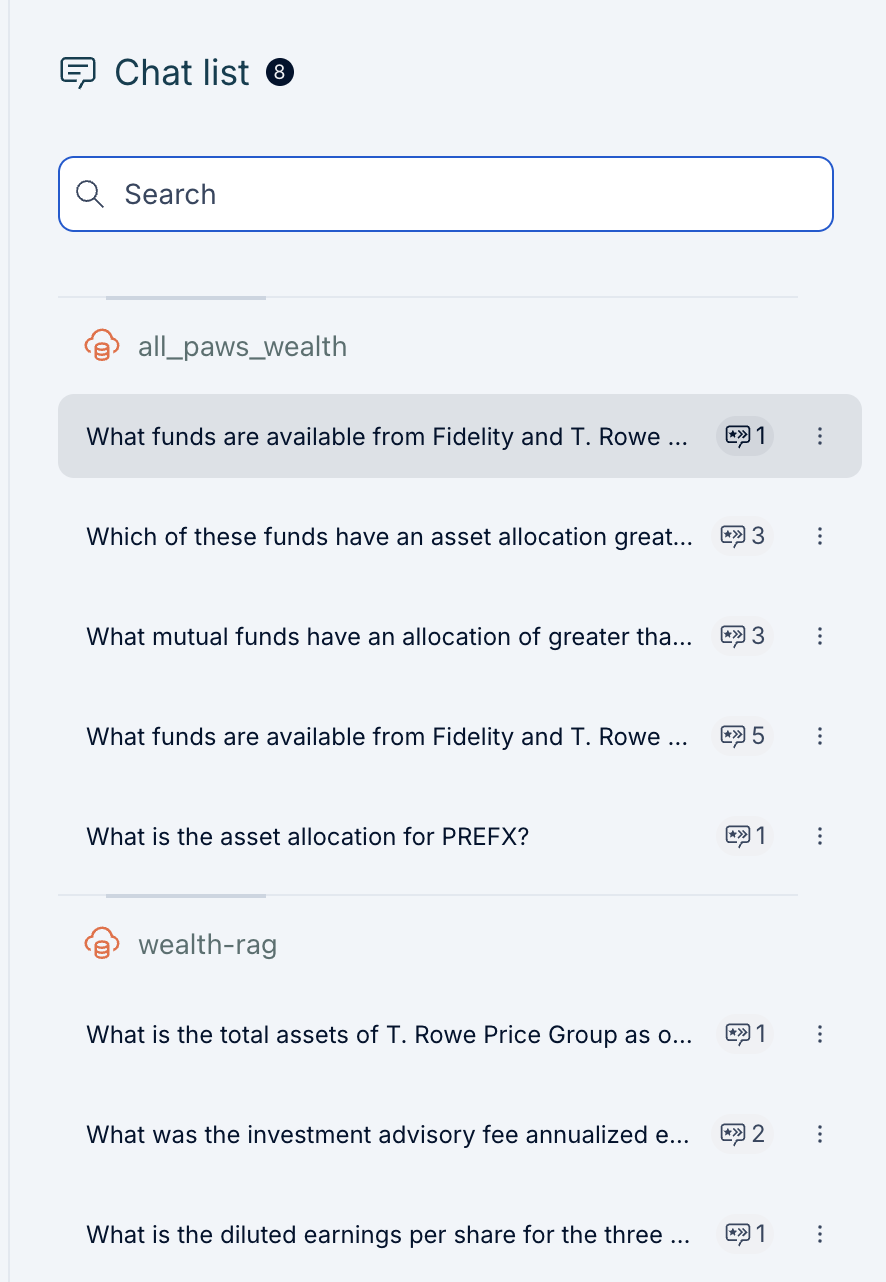
Knowledge panel
The knowledge panel provides a detailed view of the data associated with a user question or selected item. Knowledge panels can be opened in two different ways. Knowledge panels will automatically open based on a response from Voicebox with a more detailed response and structured data such as table and chart when applicable. Any instance of data from the chat panel or in the knowledge panel can be selected to open a knowledge panel specific to that instance of data. For instance knowledge panels, a summary including defined attributes and related concepts will be shown.
Users may use the knowledge panel to gain a deeper understanding of a given entity or set of entities, including detailed attributes and relationships that are hyperlinked for easy traversal across the connected data landscape. As you traverse through different information, a breadcrumb trail allows you to track the path and easily get back to the original state. The knowledge panel also highlights the lineage through the data sources icon. More details on lineage can be found in the following section.
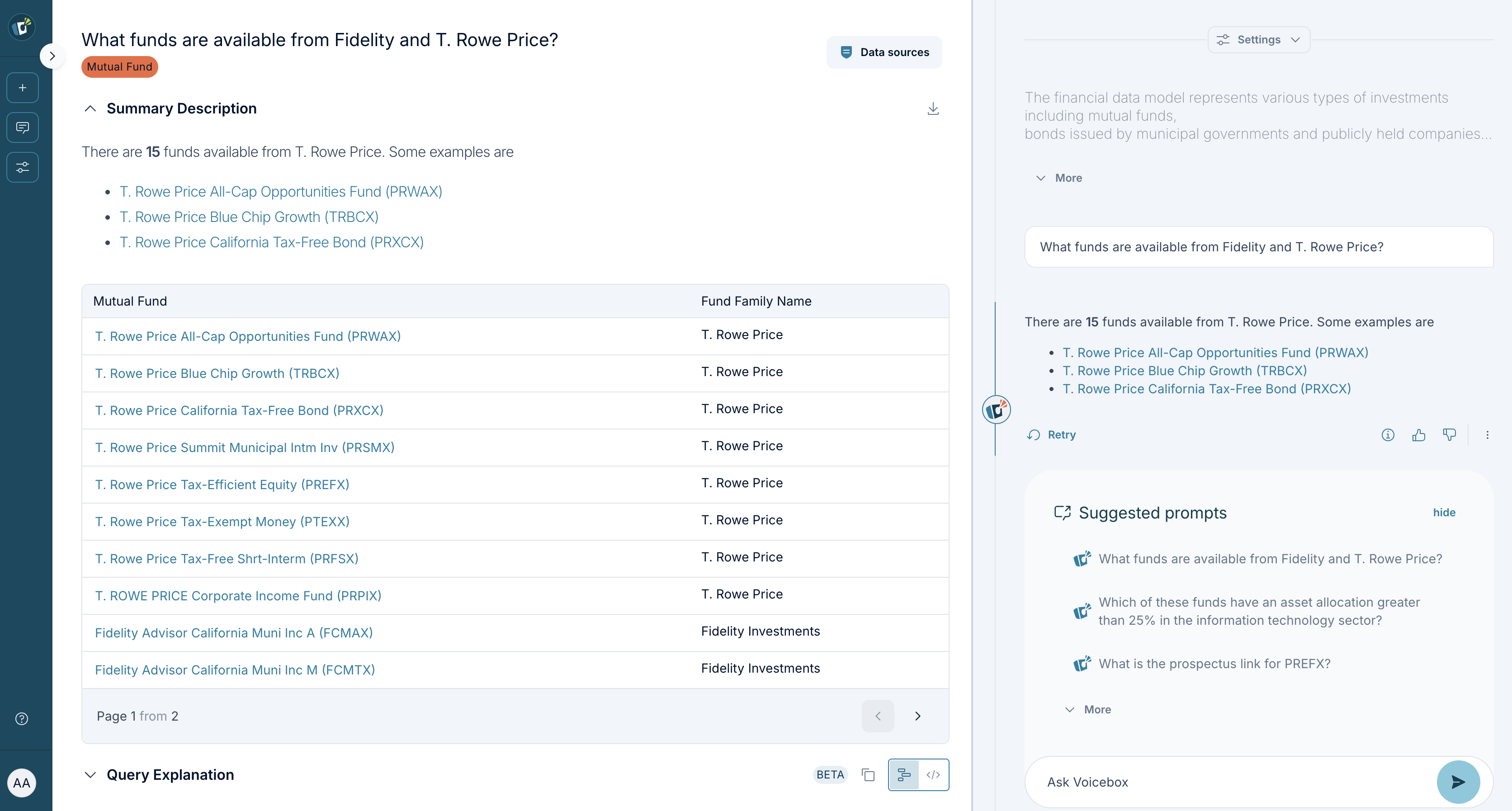
Lineage
Voicebox provides detailed lineage information, tracing the origin of data used to generate responses. This includes identifying data sources, both local and virtual. Understanding data lineage is essential for verifying the accuracy and reliability of Voicebox output.
The knowledge panel offers a granular view of the data sources involved in answering a user’s query. This includes:
- Data Source: The specific location from which the data was retrieved. In Voicebox lineage, “Data Source” refers to either a Stardog Named Graph (within Stardog) or a database table (external).
- Stardog Concepts: Stardog classes that provide semantic context, specifying the type of information presented (e.g., “Mutual Fund,” “Customer,” “Product”)
- Document Metadata: Document name and Page Number (for .PDF only)
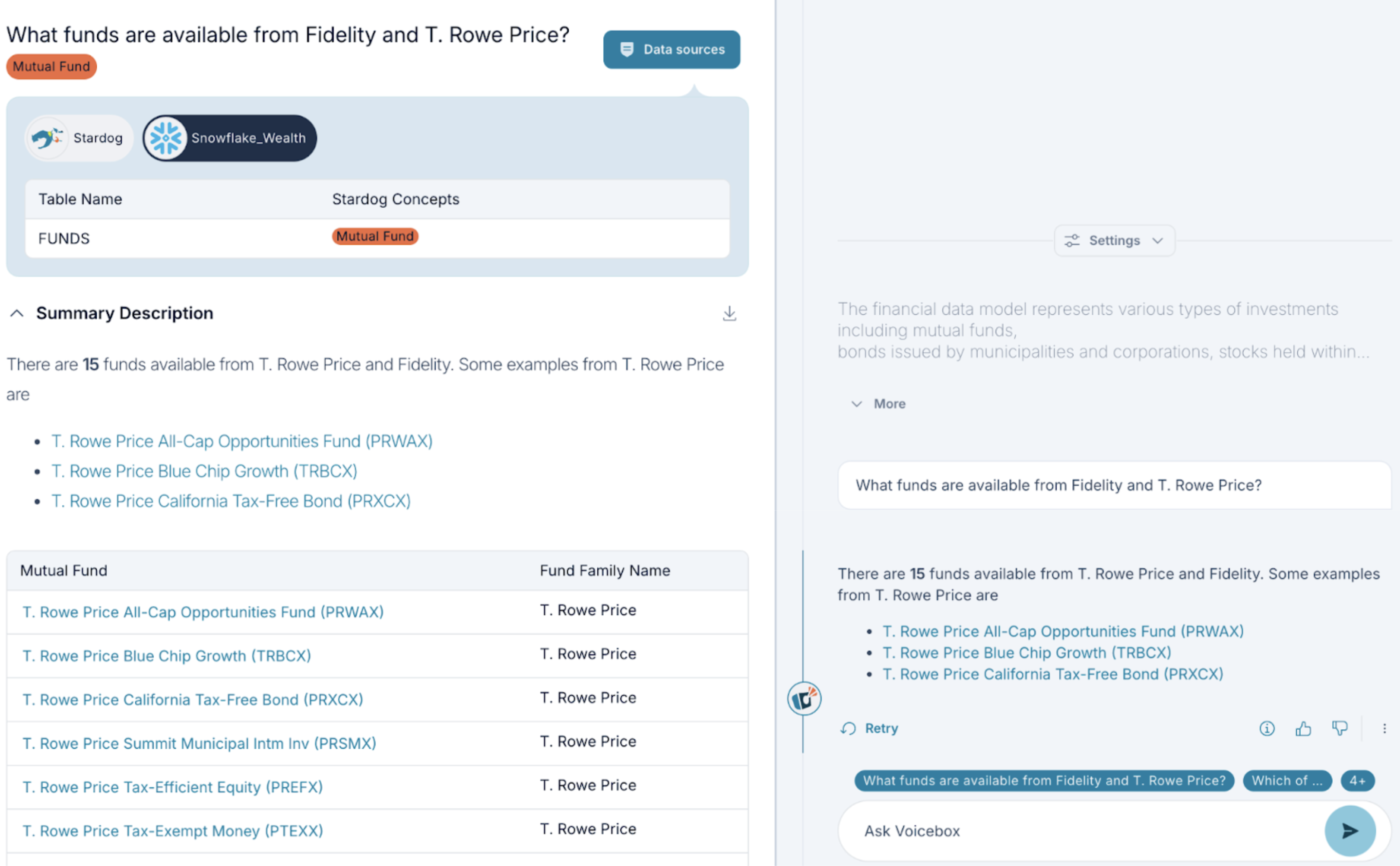
This level of detail allows users to trace the origin of information across systems, which is helpful for:
- Verifying data accuracy.
- Assessing data relevance.
- Troubleshooting data issues.
You can delve deeper into a specific Stardog Concept, such as the “Mutual Fund” class, by clicking on it. The knowledge panel will then update to show instances, attributes, and related concepts associated with that class.
Using Voicebox with Stardog Applications
Stardog Designer
Within Stardog Designer, Voicebox serves as an assistive tool for ontology development. It enables you to:
- Ontology Creation Based on Use Case Description: Voicebox enables you to create new elements for your ontology based on real-world scenarios. For example, you can describe a retail store’s data needs, and Voicebox will help you add relevant classes, relationships, and attributes to accurately represent that use case.
- Create and Modify Model Concepts: You can easily introduce new elements to your ontology, such as classes, relationships, and attributes, and update existing ones within your data model.
- Bulk Editing: Voicebox allows for efficient changes across multiple elements. For instance, you can modify all class labels to be singular, add descriptions to several attributes at once, or update namespaces throughout your ontology.
Voicebox aims to make the process of building and maintaining your ontology more intuitive and efficient.
Stardog Explorer
Stardog Explorer leverages Voicebox to provide a natural language interface for querying your knowledge graph. By posing questions in plain language, Voicebox translates your queries into SPARQL, retrieving the relevant data from your graph. Explore a result by clicking on the linked Voicebox response. This feature makes knowledge graph exploration more accessible and user-friendly.
Stardog Studio
Voicebox in Stardog Studio responds to natural language questions with a SPARQL query. By posing questions in plain language, Voicebox translates your queries into SPARQL providing even the most technical users an option to accelerate their query writing. The returned SPARQL is written directly in Studio’s workspace, so users can modify and expand as needed.
Personalizing Your Voicebox Experience
Setting up a knowledge base for use with Voicebox
Voicebox experiences can be customized based on specific models/ontologies for a given use case that capture key business concepts and relationships, including custom rulesets and constraints, relevant to the domain and user personas. This design paradigm is available through our Designer application and published models/ontologies along with the business logic can be configured for use with Voicebox. The settings panel allows you to configure a Voicebox experience to the specific knowledge database and models specific to the user needs.
Rules can be used to infer additional data based on patterns in your knowledge graph. An example of a rule setup in Designer - a supply chain analyst can specify a rule that can infer an anomaly if the conditions below are met against data accessed at query time. These rules can be changed and additional rules may be added which allows users to put multiple lenses over the same data.
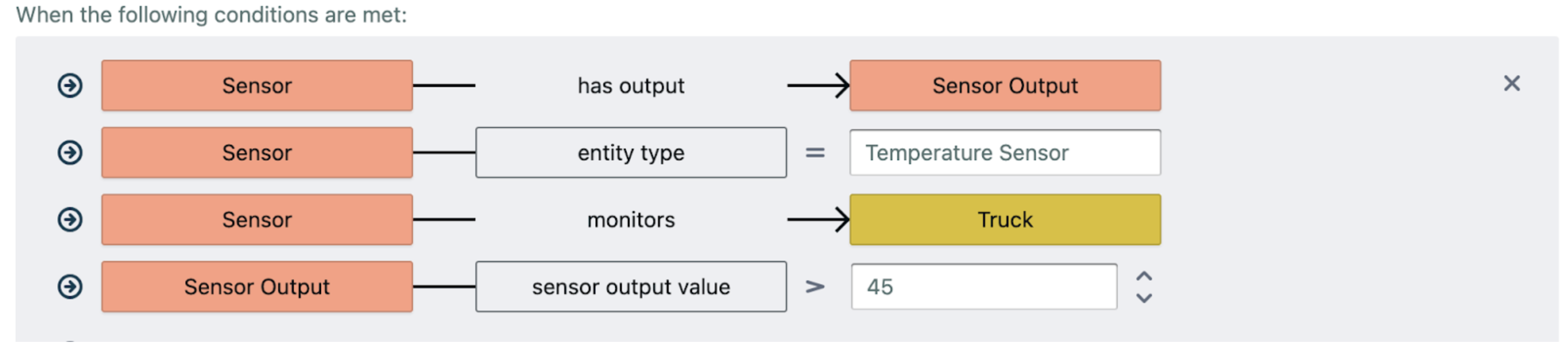
Building few-shot examples
The accuracy of Voicebox related to customer-specific domain knowledge can be improved through the development of prompts as few-shot examples. Few-shot examples provide Voicebox with question-answer pairs, enabling adaptation to new or less common query patterns, relevant to the domain and use case. Few-shot examples can be developed by subject matter experts using a no-code visual interface in Stardog Explorer. Implementation details are available in the Voicebox Developer Guide. Examples can be refined based on user interactions.
Setting up spotlight questions
Spotlight questions are pre-defined queries that highlight key insights or frequently accessed information within the knowledge graph. These questions provide direct answers to common queries, and administrators can define questions relevant to specific business needs. Configuration and management details are available in the Voicebox Developer Guide. Questions can be updated to reflect data or business changes.
Providing feedback to answers
- Thumbs up/down: After Voicebox returns an answer, you’ll have the option to thumb up or down the response.
- Additional feedback: There is also an optional space to provide additional comments for your feedback. Your feedback will help us continue to improve Voicebox’s responses.
We don’t use actual customer data to train or finetune our models.
Multi-Agent Orchestration
Agents
These agents are currently only available as part of a private preview.
Voicebox employs a suite of specialized agents, each designed to perform specific data tasks, enabling users to interact with and analyze data in a targeted manner. These agents operate autonomously, selecting the most appropriate tool for the given query.
- History Agent: Tracks conversational context as short term memory to support multi-turn conversations. #nohistory can be used a hint to break the conversational context memory.
- Router Agent: Intelligently identifies the right agent to engage.
- Entity Description Agent: Retrieves detailed information about a specific entity from the Knowledge Graph.
- Dataset Description Agent: Provides a description of the schema for a given data source or Knowledge Graph.
- KG Query Agent: Generates and executes complex queries against the Knowledge Graph to retrieve specific data.
- Chart Creation Agent: Generates visualizations, such as charts and graphs, to represent data. #chart can be used as a hint to invoke this agent.
- Data Analysis Agent: Performs calculations and data transformations, including tabular data analysis on the results retrieved from the KG Query Agent. #compute can be used as a hint to use this agent.
- Response Summarization Agent: Summarizes the response back to the user in plain language.
- External LLM Agent: Leverages the general knowledge base of the LLM as part of its response back to the user. Note: This may contain Hallucinations. #llm can be used as a hint to invoke this agent.
- RAG Agent: Retrieves text, table data and document metadata for a given user question.
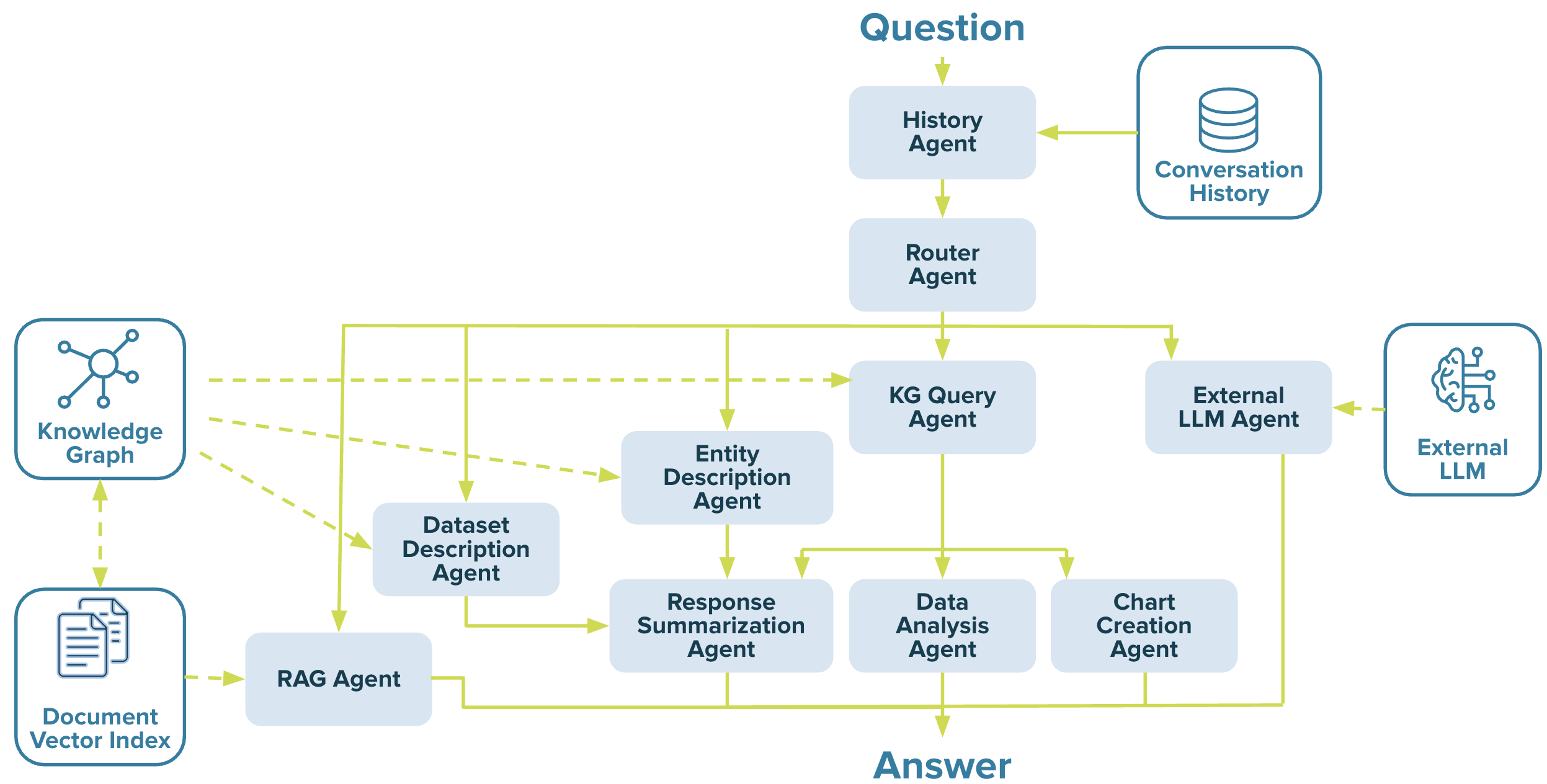
Voicebox agents are equipped with tools that enable automatic labeling and categorization of user queries, the generation and execution of code for specific tasks, and the creation of summaries for tabular data.
Retrieval Augmented Generation (RAG) pipeline for unstructured text
Voicebox can process questions based on unstructured documents, such as financial, technical, compliance, and regulatory documents. To enable this, an ETL pipeline is used to index these documents as embeddings within the built-in vector store of the Stardog Platform. This ETL pipeline utilizes Spark to stream from various document stores, currently supporting MS One Drive, Google Drive, and local storage with current support for reading .PDF and .DOCX file types, chunking text information with enhanced intelligence to chunk embedded table content in these documents. The diagram below illustrates this process.
Detailed instructions for executing the RAG pipeline are available under the Using Unstructured Data with Voicebox section of the documentation.

Additional Tips for Interacting with Voicebox
- Align your language with the data context. Pay attention to the terminology used within the data you are querying. This will help Voicebox accurately interpret your requests.
- Be as specific as possible. Providing detailed criteria in your query will yield more precise results.
- For instance, “List the top 10 most prescribed medications for patients over 65” is more specific than “Top 10 prescribed medications.”
- Use structured, grammatically correct requests. Clear and well-formed queries are easier for Voicebox to process.
- For instance, “Find all customers with a credit score higher than 750 and who have made purchases in the last 3 months” is better than “Customers with 750 credit score or higher, purchases last 3 months.”